
2019: AXI Meets Formal Verification
It’s a new year! Let’s continue our end-of-year tradition from 2017 and 2018 and take a moment to look back over 2019, from the perspective of the ZipCPU blog, and see what stands out.
Blog History
If you aren’t familiar with the back story, I started the ZipCPU blog back in 2017. Back then, times were tough. It had only been four years since starting Gisselquist Technology, and contacts and jobs were drying up.
Did I know what I was doing when I began Gisselquist Technology back in 2013? While we can argue about whether I understood digital design back then, I clearly did not understand business. I knew it too.
Prior to 2017, I’d had a couple of gift jobs: friends I knew who just happened to have just the right job for me. At one time, I remember traveling to visit my mother and then visited some friends who worked nearby. These friends asked me to come visit them at the office, during business hours, and so I found myself walking into a meeting where the foregone conclusion was that they wanted me to do a job for them.
This is what I consider a “gift”–not because it isn’t valid work, nor because there’s anything untoward going on, but simply because I was the right person for the job at the right time. I walked into someone else’s need. Such jobs are gifts from the Almighty.
That said, it’s hard to plan on gifts, and I needed to learn how to find business the hard way.
My original approach to business development was to build a portfolio of digital designs on OpenCores, and then use them as discussion pieces on various digital forums. Indeed, they made great example designs for that purpose. That said, this approach wasn’t bringing in any business (at the time). (I’ve since gotten several contracts from this work.)
 |
Then, in May of 2017 my aunt came to visit. She took the whole family to the local used book store to pick out gifts that were to be from Grandma–who was getting too frail to visit everyone. At the time, I picked up a book titled, Inbound Marketing: Get Found using Google, Social Media, and Blogs. I had heard of inbound marketing before, and the concept appealed to me. Instead of cold calling prospective customers promoting my work, I’d promote my work and capabilities on a blog to the extent that prospective customers would contact me about what they wanted done, and I could make contacts that way.
The idea appealed to me, so I started up zipcpu.com and started writing blog articles. I also started creating a twitter feed–all at the suggestion of the Inbound Marketing book.
Thus began the ZipCPU blog. Since that time, my twitter following have grown to over three thousand. Wow. Thanks, everybody!
ZipCPU meets Formal Verification
Later that year, as I was preparing to head to OrConf for the second time, Edmund from SymbioticEDA contacted me. He wanted me to try out SymbiYosys, their new formal verification tool.
What was I to say? Did I need formal verification? Of course not! Why would I need some bright new gadget to help me do what I’d been doing already? What I did need, however, was marketing material for my blog. So I decided to condescend and see how this new formal verification tool worked, and then write a blog article about it.
When pride cometh, then cometh shame: but with the lowly is wisdom. (Prov 11:2)
Much to my surprise, the formal verification tool taught me some desperately needed humility. I applied the formal verification tool to a very basic design, a simple FIFO that I’d used for years, only to discover it had bugs in it that were never found by my test bench.
I then set out to formally verify the rest of my portfolio. Over and over I found bugs, sometimes subtle ones, sometimes not so subtle. I found bugs in all kinds of places, notably in designs that had passed all of my test benches: my prefetch and cache, my CPU, my SDRAM controller, my SD-Card controller, an FFT and much more. Indeed, I’ve since found so many bugs using formal verification, that I’m not sure I could go back to what I was doing before–I no longer trust my ability to write a test bench that would be “good enough”.
This has also made the blog quite unique: In a world where no one discusses hardware bugs, where bugs get quietly swept under the rug, I was discussing bugs in my own work.
Yes, I suppose the verse above is worth repeating.
When pride cometh, then cometh shame: but with the lowly is wisdom. (Prov 11:2)
Formal Verification meets AXI
 |
While most of my designs used a Wishbone bus, every now and again I needed something using AXI. So, back in late 2018, I started building a set of formal properties that could be used to verify an AXI component–much like the formal properties I’d already used for verifying my Wishbone components.
As with any project, I started off simple and just looked at AXI-lite. Unlike the full AXI protocol, AXI-lite doesn’t have nearly as many signals to it, and so it was fairly easy to work with. I began simply with the four basic bus properties I had learned to use when working with Wishbone:
- Following a reset, everything should return to idle.
- When a request is stalled, its details shouldn’t be changed
- There shall be no responses without prior requests, and
- All requests get responses.
These are pretty basic, and in the case of AXI-lite they weren’t all that hard to write out.
 |
I then looked around for a working design to try my new properties on. It didn’t take too long before I found Xilinx’s demonstration designs. Much to my surprise, I found bugs. The core would drop transaction responses, as shown in Fig’s 3 and 4 where, with just a little bit of back pressure, the second request’s response would get dropped.
The presumption, of course, was that my brand-new, untested formal bus properties were broken. This would be the only sensible conclusion. The Xilinx design I was trying to verify had been around for years. It had been used by many Xilinx customers. Indeed, you’d expect the bugs to have been worked out of them by the time I started working with them.
So I dug into the demonstration designs to see what was going on. Again to my surprise, I was able to verify that the bugs the formal tool found were indeed valid.
 |
While this took place in late 2018, this was really the start of what I’m going to call, the year when AXI met formal.
My surprise at finding bugs in Xilinx’s AXI-lite core only intensified when one of Xilinx’s engineer’s contacted me to explain that not returning a response to a transaction wasn’t a bug, since the response might yet be returned later. Indeed, from just looking at Fig’s 3 and 4 you might not catch that the trace ends in a steady state! However, if you looked at the core, you could tell that the response had been dropped and would never be returned.
I then had to explain to them that this was their IP core I had found bugs in, and not my own. Unfortunately, this took more explaining than I was expecting. Yes, I had modified the core: I had adjusted the white space, removed white space from the ends of lines, and corrected spelling mistakes in the comments. No, the logic wasn’t modified, etc.
 |
Of course, from this point out things only got easier for me. You see, now that I had a formal property file describing an AXI-lite interface, testing and checking other cores became routine. With this property set, plus the Symbiotic EDA Suite, I could now take any AXI-lite design, Verilog, VHDL, or even System Verilog, posted to any forum, attach my property file, and verify that the bus interface to such a core was (or was not) working—even before I understood all of the details of how the core was supposed to work. Several cores were forwarded to me at that time to verify. Almost all were broken, and worse most were broken in the same way. The most notable exception was an Analog Devices core–a pleasant surprise along the way since it just worked unlike the other cores I had been checking.
Now that I had my own formal property file, I could do more than check the properties of others, I could now build my own AXI-lite slave core as well. At this point, it was easy to do. Fig. 6 shows the kind of throughput I was able to achieve on the write channel,
 |
and Fig. 7 shows the performance on the write channel. In both cases, I was able to achieve 100% throughput–shown at the end of the traces above. This is in contrast to Xilinx’s demonstration cores which achieved only 50% throughput in Vivado 2016.3 (less in 2018.3) and many of Xilinx’s AXI full IP cores.
 |
I then turned my attention to building a full AXI4 property set, rather than just the AXI-Lite version.
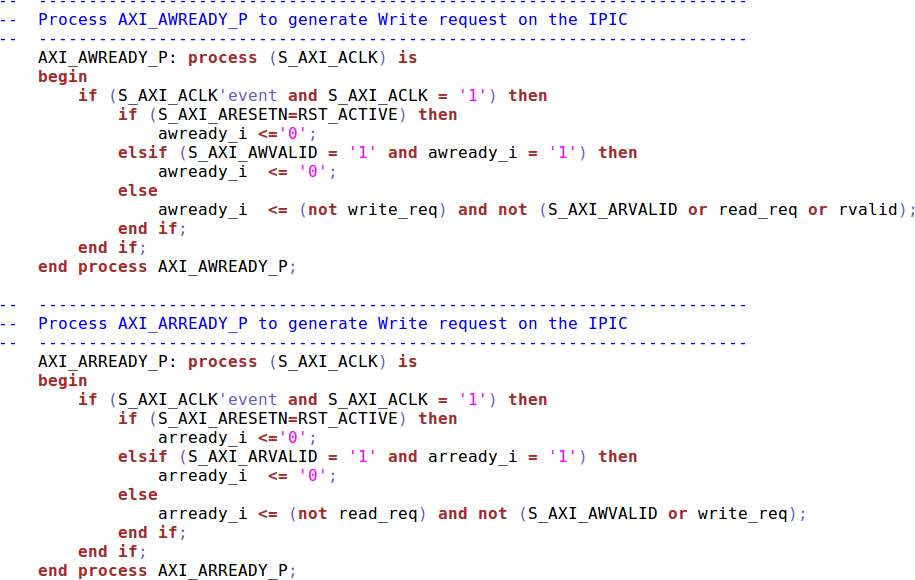
AXI4 was much more of a challenge to formally verify, and that for a couple of
reasons. First, the IDs make things challenging. An AXI slave is allowed to
return transactions in any order, as long as all of the transactions associated
with a given ID are returned in order. Second, the burst lengths are a
challenge. In particular, it can be a challenge to verify that the RLAST
signal is properly set after two or more read address requests have been
accepted. In any implementation, a FIFO would fix this kind of problem nicely.
Indeed, AXI processing and FIFOs work well together. This of course led
to the third problem: verifying properties of the output of a
FIFO can be quite a challenge.
When designing an AXI component, these various constraints aren’t really all that hard to deal with. The various transaction information may be placed into FIFOs within the slave, and dealt with accordingly–but how shall these extra properties be handled in the context of formal induction?
If you haven’t worked with induction before, you should at least know that induction has its own particular challenges. In particular, the formal engine will start in the middle of time–with your design already in some state. Only your assertions and to some extent your assumptions will hold that state consistent. While it is possible to provide assertions to describe every item in a FIFO, it’s typically an expensive and challenging thing to do. But without doing this, it would be easy for the design and the formal properties to get into an inconsistent state.
 |
With some help from Clifford, I managed to put a set of AXI properties together.
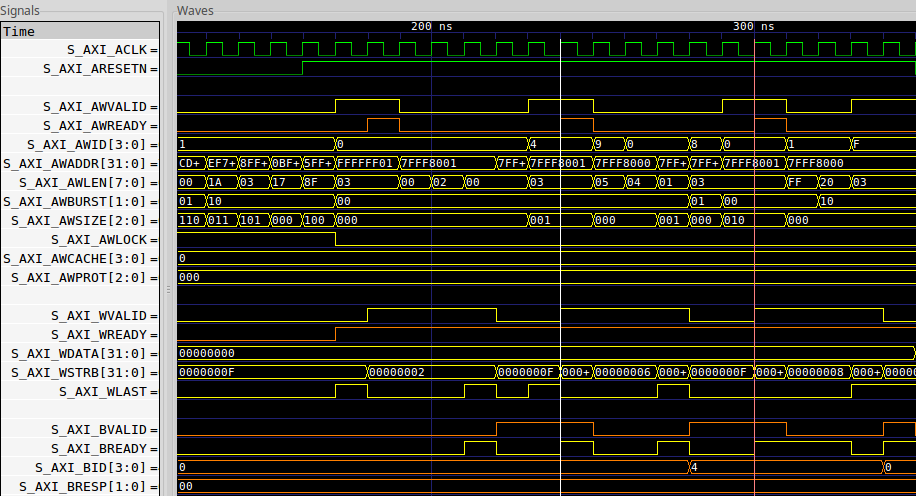
As before, I first turned to one of Xilinx’s demonstration cores to test my properties. Again, to my surprise, Xilinx’s demonstration AXI4 (full) IP was also broken.
First, it didn’t guarantee the right packet ID would be returned on either read (Fig 8) or write channels. Second, the write channel couldn’t handle backpressure as shown in Fig. 9.
This left me somewhat perplexed. How could such example designs have been broken for so long? Indeed, Xilinx was using their examples in all of their training material. Surely these examples would’ve been important for them to get right?
 |
After a bit of digging, I discovered reports of AXI designs that would hang dating back several years. Customers trusted Xilinx’s demo designs, and so believed the bugs were elsewhere–but then struggled to find the problem that was causing their design to lock up. Forum moderators typically blamed customer designs, since no one was able to reproduce the bugs in a test-bench. Not only that, but not all interconnect configurations or transaction combinations would trigger the bugs. Many of the more common interconnect configurations wouldn’t trigger the bugs at all. However, if you then switched configurations, the bug would get triggered and you’d end up looking in the wrong place.
 |
I then discovered that Xilinx would delete forum posts of dissatisfied customers, or of posters who would complain of broken infrastructure. Indeed, Fig. 11 shows a comment recommending the use of formal methods, the only method that has so far found these sorts of bugs, that Xilinx deleted from their forums.
 |
No wonder why the bugs went so long without ever getting fixed.
During this time, I had the opportunity to speak with Xilinx’s representatives as well. Thankfully, they (eventually) acknowledged the faults in their demonstration cores.
 |
Xilinx’s explanation was that these “IP Packager” cores, the ones I call their demonstration cores, came from an uncertain open source origin and were never placed under Xilinx configuration management, and so they were never verified along with the cores Xilinx considers their IP. I was then assured that Xilinx’s proper IP cores would never have these problems. Those were verified by a “best in class” verification methodology (not formal) every night, so I could rest assured that these other cores were bug free. No, this “best in class” verification methodology did not use their AXI VIP. (I asked.) Apparently, they didn’t even trust their own Verification IP for this purpose.
 |
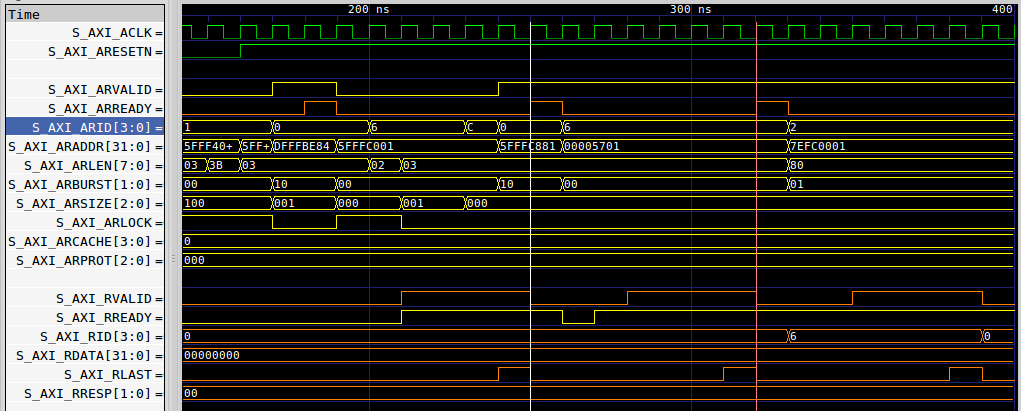
I didn’t stop with Xilinx, however. I checked out Intel’s demonstration core too. This one was an AXI3 core, and so not quite the type of AXI4 core my properties had been built to handle. On the other hand, if you limited the proof to looking at one ID only, then it wasn’t hard to use the same properties for both.
Just like Xilinx’s demonstration core, Intel’s was broken as well–in multiple
places. Fig. 13 shows a burst request, attempting to send AWLEN+1 or two
words of data, but where BVALID is set high before the second WDATA element
was received. Not only that, WREADY was dropped. Like the Xilinx bugs
above, this would likely cause the design to freeze.
Nor was this the only bug. Fig. 14 shows an example where just a little bit of back-pressure from the first burst would cause Intel’s core to drop the second response.
 |
The story didn’t stop there, however. Now that I had a formal property set to describe AXI4 transactions, I could verify just about any AXI4 interface. Doing so was as easy as creating a wrapper for the design in question, attaching the formal property set and the core in question to the wrapper, and then running the formal tools. Running the test rarely required more than a lot of typing.
As an example, I recently applied the Symbiotic EDA Suite, to Xilinx’s AXI Ethernet-Lite IP core. Here’s what I discovered:
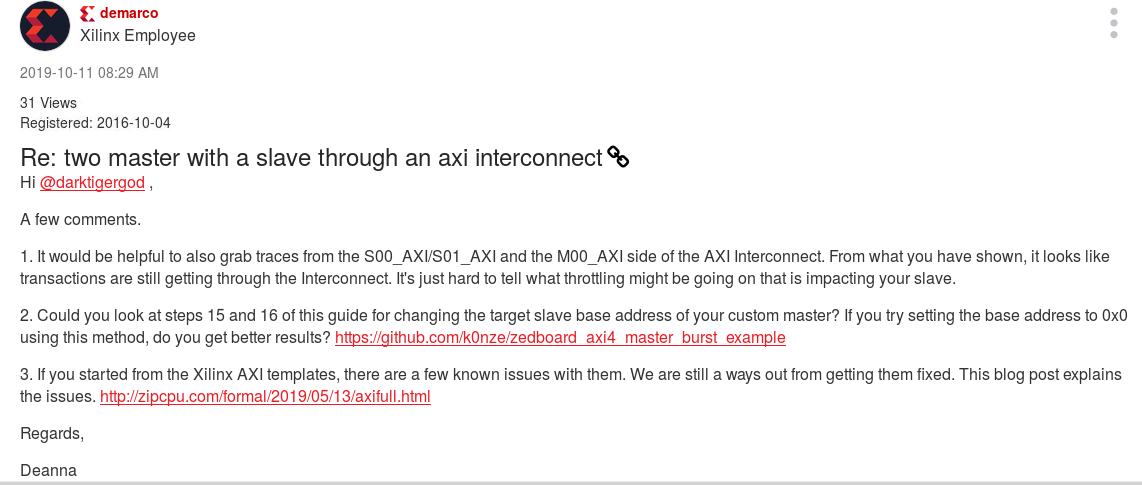
- Contrary to spec, Xilinx’s RVALID logic requires RREADY to be set
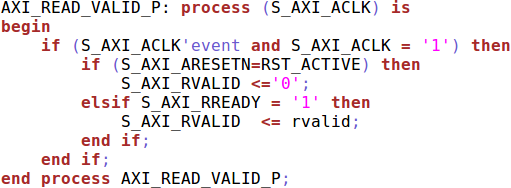 |
- This means that the design will hang if the interconnect doesn’t hold RREADY high during any read request
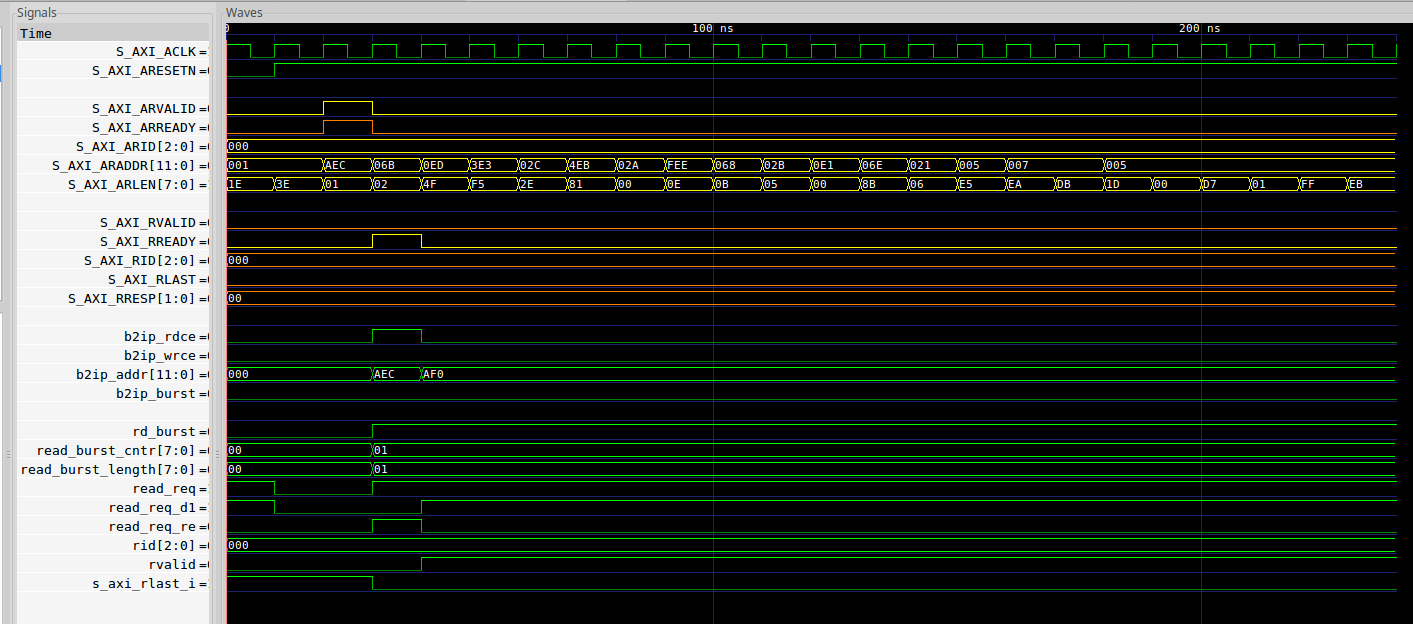 |
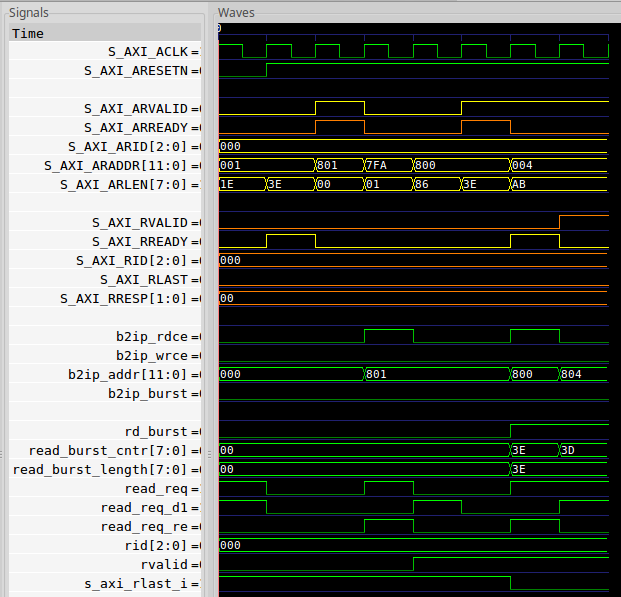
- Not only will the design hang waiting for the master to raise
RREADY, but it will also accept new requests during this time. The resulting returns might then have the wrongRID. Fig. 17, for example, shows a request of lengthARLEN+1or one data value using ID3'b101. The response then comes back with anRIDof3'b100–an error, since the3'b100response needed8'h91values before getting a return withRLASTset.
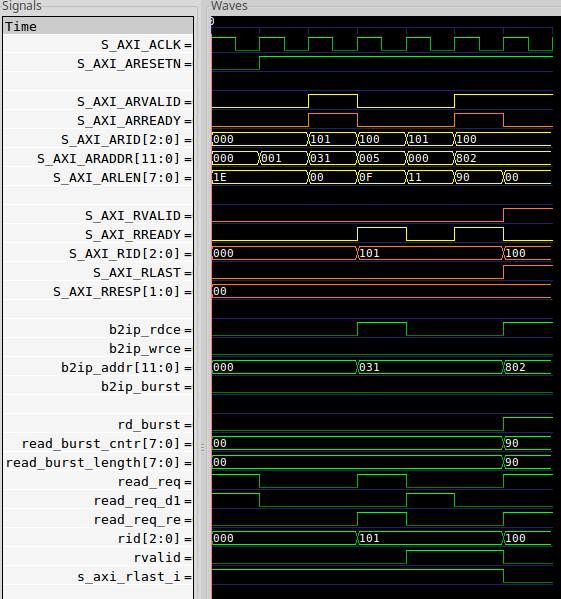 |
- Returns might even be given the wrong
RLAST. While Fig. 17 hinted at this problem, you can see it clearly in Fig. 18 below. In this case, two requests are made forARID=3'b000. The first request is for a single beat, the second for1+8'h3Ebeats. However, when the core responds to the first request,RLASTis still low. The cause? Primarily the simple fact that this core can’t handle backpressure.
 |
- If all of that wasn’t bad enough, writes accepted at the same time reads
are accepted will write their values to the address given on the read
channel. You can see this by examining the code from their design.
If you want to check your own install, check out the
axi_ethernetlite_v3_0/hdl/axi_ethernetlite_v3_0_vh_rfs.vhdfile in your Vivado{INSTALL}/data/ip/xilinx/data/ip/xilinx/axi_ethernetlite_v3_0/hdldirectory.
 |
- To keep this from happening, their design prohibits reads during writes and writes during reads. The only problem is, they never check for read and write requests being made on the same clock cycle.
 |
Apparently, Xilinx’s professional “best in class” AXI property checker doesn’t include a formal property check. Just like my own first experiences with formal methods, they’ve now been burned by designs that passed a test bench without being specification compliant.
I’ve also applied formal methods to their Block RAM
controller. Along the way I discovered that it
could only handle reads or writes, never both at the same time–despite the
fact that AXI has channels for both. (This seems like a common theme, no?)
Not only that, but my own example
design achieved better
throughput on single channels. Here’s their best block RAM read performance,
requiring N+3 clocks to read N elements.
 |
Poor burst performance wasn’t limited to reads, but also affected the write channel as well.
 |
Let’s now think this through. These bugs were found within just a few of Xilinx’s IP cores where they’ve publicly posted their design code. How many bugs would you now expect from IP that hasn’t been posted publicly?
This is where and why open source becomes so important. When the design source is open, you can verify the existence of any bugs on your own.
To this end, I’ve also managed to verify and demonstrate several IP cores of my own using this AXI4 property set as well:
- An AXI Crossbar
-
Data movers: AXIMM2S and AXIS2MM.
These two are my own. They bare no internal resemblance to Xilinx’s (encrypted) data mover cores–or shall I say they bare no resemblance that I am aware of.
No, I haven’t verified Xilinx’s data movers as either working on not. Unlike their data movers, 1) these two cores work within Verilator, and 2) they can both achieve a 100% AXI throughput.
- An AXI to AXI-lite bridge. Better yet, an AXI to AXI-lite bridge that gets 100% throughput–meaning you can write an AXI-lite slave that can still process AXI transactions without slowing down.
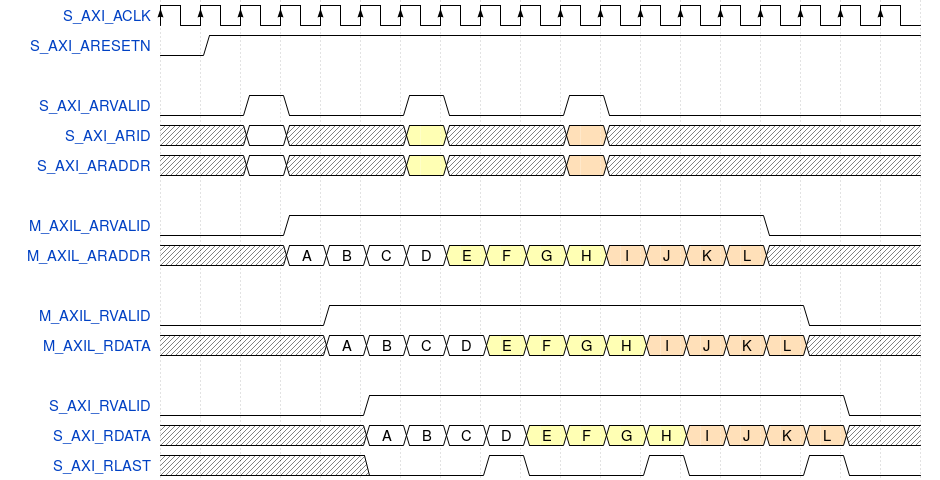 |
- An AXI Firewall, which can detect any of the bugs discussed above, forcing a slave to either be compliant or to be reset. As a special bonus, the slave can be reset and re-integrated into the design–without either hanging or propagating any non-compliant responses upstream.
None of these insights would’ve been possible without either the Symbiotic EDA Suite, or the formal AXI4 property set for verifying AXI cores.
The New Tutorial
In the middle of all of this, I also built a beginners Verilog tutorial. My work on this tutorial started in 2018, although it took until May of 2019 for me to finish it. The tutorial was initially intended to be something that could be used as a set of lecture slides for a class. As a result, it consists of a series of PDF files and some partially completed (and deliberately broken) homework exercises.
Unlike many other approaches, my own approach doesn’t teach the full Verilog test-bench syntax. Instead, I chose to use Verilator and C++ design wrappers. My reason was simply due to the fact that I’d seen so many students get confused when attempting to synthesize what should’ve been test-bench only code.
The second big difference with my approach was that I taught how to apply formal verification to every design, starting in lesson three.
The third big difference was that I tried to be hardware agnostic. All you needed was a simulator–in this case, Verilator. As a bonus, if you had an FPGA, any FPGA with nothing more than serial port, a button (or switch), and several LEDs, you could build all of the designs for your board. Indeed, I avoided proprietary design components like the plague–in order to keep the tutorial fully generic.
The course has been well received, albeit with caveats:
-
Students with some Verilog background have balked at my liberal usage of C++ and Makefiles. Why, they’ve asked, should they be required to learn a new language? This is understandable. On the other hand, students with more of a software background have likely felt quite at home with this approach.
-
Since the rest of the industry uses Verilog test benches (or SystemVerilog, or VHDL …), the tutorial has often left students either without this valuable skill or wondering how they should be using it.
-
Since I used Verilator and the open version of SymbiYosys for all of the projects, there was no ability to add a parallel VHDL tutorial. Many students have asked for one. This is currently something that I am unable to provide using free tools.
-
Because I used PDF files, I can’t track downloads. This makes it hard to know if students are really interacting with the tutorial itself, or perhaps just the formal verification courseware slides that are further down on the same page. I suppose it doesn’t matter, both would be good things, I’d just love to know and understand more about my readers.
Finally, several individuals have asked for a course that goes into the next step–an intermediate design course. Such a course would teach design in the context of a system with either a Wishbone or an AXI-Lite internal bus.
 |
At this point, however, my world tutorial domination plans have gotten slowed down. Specifically, I want my intermediate design tutorial to remain vendor agnostic–while still being useful on SOC (FPGA+ARM) chips. That means that the tutorial will need to teach students how to connect bus components to a design using only open source tools.
As of today, I think I’ve finally got AutoFPGA lined up for that purpose. It now has an (untested, and quite likely buggy) development branch that supports not only Wishbone (pipeline), but also AXI-lite and AXI–with an appropriate set of crossbars, bridges, and bus simplifiers to make certain things work together properly.
 |
If the Lord is willing, I look forward to finally getting some of the lessons associated with this course written in 2020.
Viewership in 2019
With all that background aside, it’s now time to turn our attention to some statistics from 2019. Care to see how well the blog has done? As you can see from the chart below, the ZipCPU blog has really taken off this last year.
 |
Last year, the blog had 183,281 page views. This year, we’ve had 332,735 page views. Readership is definitely up.
Even better, the blog has gone from a maximum of 647 page views per day within a week, shown on the far left of Fig. 26 above, to 1,984 page views in one day during one week in December. This is nearly a three-fold increase in the number of page views.
If you are new to the blog, then, welcome!
That said, if you want to sell me web software to help my blog get noticed by the big search engines, then No, Thank you. The blog is doing quite nicely on its own.
Another thing to notice that’s fascinating about this chart is that most of the page views take place between Monday and Friday. This tells me that the ZipCPU blog isn’t just read by hobbyists–apparently the professionals find this information quite relevant as well.
Welcome, professionals!
Third, you’ll notice that readership slowed somewhat during June and July. Initially, I attributed this to the fact that I was working on so many contracts that it was difficult to write new articles. Now, looking over the months since then, I’m not so sure. Instead, I’m more tempted to believe that this slump is due to the end of the school year and either students not reading the articles, or professionals going on vacation.
Finally, I think that in many ways the reason why the blog took off this year is because of my AXI work above. I was pleasantly surprised to see how many hits the various AXI articles received, as I’ll discuss in the next section.
Top Articles Written in 2019
Let’s now look at some of the most popular articles from 2019. As we did last year, I’ll treat these as a top ten list, and work my way from number ten (least popular) down to number one (most popular). I’ll also continue my tradition of splitting the lists into two. The first list will consist of the most popular articles written in 2019, and then in the next section we’ll look at a list of the most popular articles over all based upon what was viewed in 2019.
I’ll start with two honorable mentions.
-
AXI Verification, the story so far
While this article didn’t quite break into the 2019 top ten, to me it tells the story of what’s been going on, told in a way that even a manager might understand it. In short, user after user has tried to build an AXI component, likely following the demonstration guides given them by their vendor, only to find that their design will suddenly freeze for a reason they can’t seem to fathom.
The fact that these bugs were finally found using formal methods should be a lesson to all.
This article had 1,018 page views.
-
Just how long does a formal proof take to finish?
A second article to miss the top ten was this neat one on proof durations. Since I’ve now performed and maintain nearly a thousand proofs, it’s easy to draw some statistics from them. Surprisingly, as this article demonstrates, formal proofs tend to be fairly fast overall–something worth remembering.
Of course, the statistic might also be biased by the fact that I always use induction. Without induction, it’s hard to know how much formal verification is enough. With it, proofs can confidently be shortened to a minimum length.
That said, I’ll let you read more about this yourself if you’d like.
This article had 1,130 page views. It is currently the #1 result of a duckduckgo.com search on how long does a formal proof take. I would share Google search result rankings, except that Google seems to know what I’m looking for even before I type anything. This is why I’m posting duckduckgo search result rankings.
-
This is a fascinating article because it walks through the steps I went through to find a fault within a design where the ZipCPU suddenly froze mid-program. It walks through and describes the various tools which can be used to debug a CPU design, and then discusses how they did (or did not) help in this case.
The bug in question was a particularly ugly one too–involving a race condition between the interrupt line and the compressed instruction word decoder. In the end, a watchdog timer connected to an internal logic analyzer was used to provide evidences of the bug, evidences which were then be placed into a formal verification context to find the details surrounding what caused the bug.
Looking back over the article today, it’s a fond memory and a fun read.
This article had 1,184 page views. It is currently the #1 result of a duckduckgo.com search on Debugging a CPU.
-
Breaking all the rules to create an arbitrary clock signal
One of the first rules I give to beginning digital designers is that you should never, ever, transition your logic on the positive (or negative) edge of something that isn’t a bonafide clock signal. Never. Just … don’t do it. There be dragons there.
In this article, however, I poke into the issue to see if a clock can be generated at an arbitrary clock rate using logic and an OSERDES. Sure enough, I demonstrate FPGA-based clock generation with sub-Hz resolution and less than
1nsphase noise.Yes, folks, it can be done! Even better, the design isn’t all that hard to understand either.
This article had 1,233 page views. It is currently the #1 duckduckgo.com hit for arbitrary clock generator example.
-
Lessons learned while building Crossbar Interconnects
Most of the designs I’ve reviewed on either Digilent’s or Xilinx’s forums include some form of an AXI Interconnect within them. Indeed, my own Intel Cyclone-V design starts with the AXI Interconnect output from the ARM SoC. These are very vendor dependent interconnects. They are proprietary, encrypted, and cannot run under Verilator.
Building my own interconnect was therefore a necessary part of building a vendor independent infrastructure. Sure, I hear the question now, but aren’t you a vendor? I suppose you might say that. However, I’ve posted the design files for my (unencrypted) interconnect(s) online–so feel free to use them as you need them.
Sadly, an interconnect is really too complicated for a blog article. So, instead, this article discusses the design of an interconnect in broad brush terms so you can see how one might work and what the various internal components might look like.
This article had 1,428 page views. It is currently the #2 duckduckgo.com hit for crossbar interconnect.
-
Building a Universal QSPI Flash Controller
After building about four other flash controllers, it was time to see if I could build one that might work for all of my designs, across all of the various flash components I’ve worked with, while maintaining high speed.
This article, one of my longer ones, goes through what it took to do this, while also describing how design bloat took hold to make this one-size-fits-all design more complex than a special purpose controller would have been. Indeed, at one point I named this a piece of Franken-IP.
Of course, the devil lies in the details. Since writing the article, I was disappointed to discover that the core didn’t support a flash design that had neither DDR support for the flash clock, nor XiP support. Of course, this didn’t happen on any of my hardware …
This article had 1,696 page views. It is currently the #4 duckduckgo.com hit for QSPI flash controller, behind (among other things) my own QSPI flash controller core on OpenCores.
-
Examining Xilinx’s AXI Demonstration Core
As mentioned above, one of my first tasks after building a formal property set for the full AXI protocol was to verify a core using it. This article discusses all of the bugs I found when verifying Xilinx’s AXI demonstration IP core.
This article had 1,873 page views. It is currently the #16 duckduckgo.com hit for Xilinx AXI slave, falling behind my own article on Building the perfect AXI4 slave at #11.
-
Building a Skid Buffer for AXI Processing
AXI has a particular requirement that there can be no combinatorial paths between AXI inputs and outputs. This applies most painfully to the
xREADYwires. The easy way around this is to use a skidbuffer, as discussed in this article. Indeed, creating a skid buffer makes building AXI logic so easy that I’ve since been converting all of my designs so that they use them explicitly. If you want to see an example of this, check out the data mover cores: AXIMM2S and AXIS2MM. These both have a skidbuffer based AXI-lite interface–one that was almost as easy as a Wishbone interface to write.This article had 2,003 page views. It is currently the #1 duckduckgo.com hit for skidbuffer.
-
After verifying Xilinx’s AXI-lite and AXI (full) demonstration cores, as well as Intel’s cores, and after looking over several examples of on-line cores, it quickly became apparent that the same bug was being replicated across many designs. This article discusses that bug, showing how it may easily be spotted, and how to adjust your design so it doesn’t have that bug.
This article had 2,436 page views. It is currently the #1 duckduckgo.com hit for AXI mistakes.
-
Building the Perfect AXI4 Slave
It’s not enough to just criticize the IP of others, at some point you need to generate your own. This article discusses how to generate an AXI4 slave. It also introduces my own goal for AXI based designs: 100% throughput without stalling between requests. This is better than the
N+3(burst length plus 3 clocks) performance of Xilinx’s block RAM controller, while also offering concurrent read and write performance.Since writing this example, I’ve added several more of my designs to this mix–all with the same design goal: 100% throughput across burst boundaries. I’ll admit, getting the data movers to meet this standard was a challenge, but all very possible using SymbiYosys together with the formal property set mentioned above.
Sadly, many new FPGA designers want to know how they can build AXI4 components as well. Having read this article, they’ve often complained that it is too difficult to understand. At this point, I’m at a loss: is my development really that complicated? Or is the problem the simple reality that the AXI protocol is a complicated protocol? Do I blame Xilinx for choosing AXI, when other protocols such as Wishbone are so much simpler? Or should I blame a problem on unreasonable expectations?
Let’s face it: AXI is hard. Building bug-free AXI components is not something many professionals are good at, much less brand new students and hobbyists. This should be well evidenced by AXI bugs listed above, bugs that I found this year–even in code that had been verified by a professional “best in class” AXI verification methodology.
What if I just want an example design I can start from? Such a design is provided by the article above. Enjoy it!
This article had 3,417 page views. It is currently the #31 duckduckgo.com hit for Example AXI Slave–behind many other hits recommending that someone use one of Xilinx’s broken designs.
-
Using a Formal Property File to Verify an AXI-lite Peripheral
While technically not a 2019 article, my first AXI-lite article deserves an honorable mention in this list. This is the article that first pointed out the bugs in Xilinx’s AXI-lite demonstration core. It has been placed here in rank order, where it would fall if it were 2019 article.
Unfortunately, my page views per year metric of articles written in the same year doesn’t treat articles written late in the year fairly. As a result, this article didn’t score well in the few remaining days of year it was written, and so didn’t make the list last year. An honorable mention is therefore all the more appropriate for this article.
This article had 3,825 page views in 2019.
-
Building a Custom yet Functional AXI-Lite Slave
Holding the number two spot for the year among articles written this year, is an article on building an AXI-lite slave core. This follows from the AXI-lite formal property set article that just received honorable mention, and discusses how to build (and verify) an AXI-lite core. This core is special among many AXI-lite cores in that 1) it’s fully verified, unlike the other examples out there, and 2) it can achieve 100% throughput on both read and write channels.
Unfortunately, the name doesn’t do any justice to the article. It’s not a flashy name. Of course you’d want to build a Custom yet Functional AXI-lite slave! Who wouldn’t want to build such? The name, however, stands in contrast to Xilinx’s demonstration IP core which was clearly broken.
Since building this first design, I’ve had to build other AXI-lite designs, such as those for my data movers discussed above. Using the skidbuffers made building these designs so much easier, that I may come back later and rewrite this article showing how simple a full-featured AXI-lite slave component can be to write.
This article had 4,241 page views. It is currently the #4 duckduckgo.com hit for Example AXI-lite slave.
-
Finally, in the number one spot, is an article on AXI addressing. Unlike Wishbone, AXI has several extra addressing signals which can be used to capture the width of a request. Wires like
AxSIZE, for example, can be used to ensure that AXI transactions can go through resizing modules without any loss of information.That said, all that extra functionality comes with a cost in terms of complexity. This article works its way through the design of a “next-address” calculator that works across sizes, across unaligned address requests, fixed, incrementing, or wrapped burst addressing and more.
This “next-address” calculator has since formed a core part of many of my subsequent AXI designs. With little more than the inclusion of this core, it’s easy to create a core with “Narrow Burst” support.
This article had 4,665 page views. It is currently the #1 duckduckgo.com hit for AXI Addressing.
Top Articles Viewed in 2019
Let’s now turn from the most popular articles written in 2019, to the most popular articles viewed in 2019.
-
Why more gun control won’t solve our problems
This blog is not about Gun Control. It is about avoiding FPGA Hell through proper design and verification. While I have promised a certain number of articles on Christianity and/or professional ethics, this doesn’t really fit either category. However, this particular article needs an honorable mentions if for no other reason than the number of page views it has received this year.
So how does an article on gun-control make its way to a blog on FPGAs? It started on twitter. As the conversation on twitter continued, it became apparent that I would likely struggle to present my case one tweet at a time. Worse, I found myself in the regrettable position of irritating my FPGA twitter followers who weren’t interested in a discussion of gun policy. Therefore, in order to try to make a graceful exit from this situation, I wrote down my views and evidences into this article back in Feb 19, 2018.
Because the blog isn’t focused on gun control, I never linked to this article anywhere but in a single tweet. Today, this article comes in the surprising #11 position of all time popular articles viewed in 2019.
This article had 5,459 page views in 2019.
-
Minimizing FPGA Resource Utilization
The Spartan 6 LX4 is a small FPGA. Digilent sold it as part of their CMod S6 carrier module board. My goal when purchasing this design was to see if I could get the ZipCPU to run on this board. Logic was tight–there was no room a debug bus. In spite of all of this, the ZipCPU demonstrated the ability to run a multi-tasking system.
This article, coming in at #10, was all about what it took to get the logic resource usage down low enough that the ZipCPU could successfully fit into this design.
This article had 5,637 page views in 2019. It is currently the #1 duckduckgo.com hit for minimizing lut usage.
-
Using a CORDIC to calculate sines and cosines in an FPGA
CORDIC’s are common solutions used for generating sines and cosines within an FPGA. This particular article discusses the theory and math behind building one, and getting it to work on an FPGA.
What’s not said or discussed here is that CORDIC’s are relatively expensive, in terms of both computation and latency, especially when you want to get a lot of bits of precision and hardware multiplies are available to you. As a result, I may come back to this topic and discuss how to generate a better, cleaner, sinewave for less logic later.
For now, this article comes in at #9 for the most page views during 2019.
This article had 5,705 page views in 2019. It is currently the #8 duckduckgo.com hit for CORDIC example. Interesting enough, my CORDIC repository on Github is listed as the #10 hit.
-
Building a high speed Finite Impulse Response (FIR) Digital Filter
One of my earlier series articles was about filtering. In that article set, I presented the basics of digital filtering, and then some basic filters. I then showed how to verify that these filters worked using a generic test bench framework coupled with Verilator. The framework even went so far as to measure the expected frequency response of the filter, so you could therefore measure both passband and stopband cutoffs, as well as a stopband depth.
This article was the first in the set of example filter implementations.
This article had 6,208 page views in 2019. It is currently the #11 duckduckgo.com hit for Verilog FIR filter.
-
How simple can sinewave generation be? As simple as grabbing the top bit of the phase input. Want better than that? Use a quick table lookup. At just the cost of one 6-LUT per output bit, you can calculate a sinewave with +/- 2.5-degree accuracy.
That’s not bad for something really simple, and the performance is often good enough as well!
This article had 6,261 page views in 2019. It is currently the #11 duckduckgo.com hit for Verilog sinwave.
-
Digital data transmission requires a clock. In my own experience, that clock is often embedded within the data waveform itself and needs to be recovered. A PLL forms one common approach to this recovering such a clock.
There are a couple of ways to implement a PLL in logic. The classic method requires a CORDIC, a multiply, some filtering–and lots of clock ticks. All this logic comes at a cost impacting the PLLs ability to quickly track and lock to any incoming clock signal.
This article discusses a means of creating a PLL in logic but without the sinewave generator or the multiply. The result is a simple PLL, using little more than adds and subtracts, but yet one that is still very effective at clock tracking. What the article doesn’t discuss is the math required to get the tracking coefficients right. I may yet come back and explain that in a future article.
This article had 6,655 page views in 2019. It is currently the #2 duckduckgo.com hit for Verilog PLL.
-
The one article that really pulls all of this site together is the FPGA Hell article. I’m listing it here as an honorable mention simply because I don’t consider it to be one of my blog articles, but rather one of the articles that the blog and the purpose of it. That said, it’s still a favorite and so it has earned it’s place here in my list.
This “article” had 6,919 page views in 2019.
-
A second honorable mention goes to my projects page. This is where I offer quick descriptions of my various github projects, in case there’s something you might be looking for.
This “article” had 7,386 page views in 2019.
-
Taking a New Look at Verilator
Yes, I enjoy Verilator. This article discusses why. In particular, I enjoy mixing O/S calls with my simulations–allowing me to simulate serial ports over TCP/IP, SD cards with files and file systems, and even OLED or VGA graphics. Network ports remain on my “to-do” list.
This article goes over the basics of how to create a simulation using Verilator, and how you can then debug your design from such a simulation.
This article had 7,466 page views in 2019. It is currently the #6 duckduckgo.com hit for Verilator.
-
… and then there’s my FIFO article. This was written before I started using formal methods. Since writing it, I’ve found so many bugs in my FIFOs–first in the pointers, and then again in the data itself, so I no longer trust either this article or the implementation within it. Most of these bugs surround reads while empty, or writes while full.
That said, I’m really going to need to come back and rewrite this FIFO article properly, while also showing how to handle formally verifying the FIFO. Such a new article would follow the FIFO development in the tutorial, so feel free to check that lesson out if you want to see how to build a working FIFO in the meantime.
This article had 11,917 page views in 2019. It is currently the #8 duckduckgo.com hit for Verilator FIFO.
-
Crossing clock domains with an Asynchronous FIFO
The Asynchronous FIFO article, on the other hand, is much better. This FIFO starts with Cliff Cummings’ asynchronous FIFO and then applies formal methods to it.
I’ve since had the opportunity to revisit asynchronous FIFOs in order to create my own implementation–separate and distinct from Cummings’. Feel free to check out this newer implementation here if you want to take a peek. In particular, the proof runs a whole lot faster, and I no longer insist that the write reset be released in a clock synchronous fashion. (You’ll still need to meet timing …)
This article had 12,009 page views in 2019. It is currently the #8 duckduckgo.com hit for Asynchronous FIFO.
-
Some Simple Clock-Domain Crossing Solutions
The basics of crossing clock domains are fairly straightforward, and this article works through how to handle them. The article primarily discusses the basic 2FF synchronizer, but also looks at how that 2FF synchronizer can be used to create a cross-clock handshake.
This article had 13,530 page views in 2019. It is currently the #2 duckduckgo.com hit for Clock Domain Crossing.
-
Verilog, Formal Verification, and Verilato Beginner’s Tutorial
The number one web request across the entire ZipCPU blog during 2019 was for my Verilog tutorial page.
I’d like to say of a certainty that this was due to the Verilog tutorial itself. Sadly, due to the fact that the tutorial is written as a set of PDF files, and the fact that Google Analytics doesn’t track PDF viewing very well, I have no idea whether these web hits are to which lesson, which lesson might be confusing, or if these are to my formal courseware slides.
This may mean that I need to restructure this page in the future.
For now, I’ll let it simply mean that my tutorial page is well loved.
This page had 22,595 page views in 2019. It is currently the #16 duckduckgo.com hit for Verilog Tutorial, and the #1 hit for Formal Verification Tutorial.
The list isn’t quite accurate. The actual web page receiving more page views than any other was my main index page. Citing this page seems like quoting usage statistics for words like “the”–it’s just not that interesting.
Many thanks to all for making 2019 a wonderful year on the ZipCPU Blog! May God bless your new year with a peace that passes all understanding.
Behold, we count them happy which endure. Ye have heard of the patience of Job, and have seen the end of the Lord; that the Lord is very pitiful, and of tender mercy. (James 5:11)