
Upgrading the ZipCPU's memory unit from AXI4-lite to AXI4
Some time ago, I presented a very simple AXI4-lite memory controller for the ZipCPU. At the time, I mentioned that I also had a similar memory controller for AXI4 (not-lite). Today, let’s discuss the difference between these two controllers, to see how AXI4 excels over AXI4-lite. As you’ll see, a large focus of this discussion will focus on the exclusive access capability specific to AXI4.
Perhaps you’ll remember the discussion of today’s memory controller from the article on measuring AXI4 performance. In that article, we discussed and compared the performance of the various ZipCPU memory controllers:
-
The slowest memory controller in that test was the basic, low-logic, memory controller that we’ll be discussing today.
-
I also tested a pipelined memory controller. The claim to fame of this controller is that it will allow multiple requests to be outstanding at a time. The primary difference between this pipelined controller and the basic controller in today’s discussion is that the pipelined controller contains a FIFO and some extra counters in order to keep track of the outstanding transactions. When running Dhrystone, the ZipCPU is about 9% faster when using the pipelined controller rather than the basic controller we’ll be discussing today.
-
I also presented an AXI Data Cache based memory controller. Despite being a very basic and simple data cache implementation, the performance of a 4kB data cache still beat out today’s basic controller by 27%. This should help illustrate one of the fundamental lessons of CPU logic design: you can buy CPU speed with logic.
 |
As I noted in my recent briefing to ChipExpo 2021, I currently have no good AXI4 master for testing the AXI WRAP capability of a slave. The natural master one might have for this would be a CPU cache implementation, much like my AXI data cache, so you might see an upgrade in the near future so that it will support this capability.
For now, however, I’d like to focus on the differences between the basic AXI4-lite memory controller for the ZipCPU and its AXI4 (not-lite) counterpart. There are three big differences that we’ll discuss today, as well as two features that I’d like to discuss because I didn’t end up using them.
-
The big new feature from AXI4 over and above AXI4-lite is exclusive access. Exclusive access support is a required capability in order to support atomic actions on a busy bus, yet without bringing the other users of the bus to a halt. This is something I haven’t really blogged about before, so these changes should be interesting to discuss.
-
One of the non-trivial differences in the upgrade from AXI4–lite to AXI4 was associated with setting the AxSIZE field. This should have been trivial. Subtle requirements, both from the bus and the CPU, guaranteed that this piece of the design was far from trivial, and so I’d like to spend a moment discussing why the AxSIZE field was a challenge.
-
AXI offers two prominent features that I did not really use in my controller: IDs and multibeat bursts via AxLEN. The story of these two features, and particularly why I didn’t use AxLEN to implement bursts, is important for discussion.
-
This still leaves us with a lot of unused features, so we’ll then quickly drive those to default values in order to close out the differences between the two designs. That leaves only a small discussion at the end regarding what default values should be chosen.
That’s our basic outline, so let’s go ahead and dive into the changes required to add exclusive access to this design.
Exclusive Access
The ZipCPU has a very simple exclusive access capability. It’s one of the few functionalities that require a multi-instruction sequence.
An atomic operation
in the ZipCPU is a four instruction
sequence, starting with the LOCK instruction. The other three instructions
are a load, an ALU
operation, and then a store instruction as shown in the following
pseudo-assembly:
LOCK
LOAD (Addr),Rdata ; Load something into Rdata
ALU Rx,Rdata ; Operate on Rdata
STORE Rdata,(Addr) ; Store the result in the original addressThis format has been sufficient to implement a large number of atomic operations. For example, an atomic increment can be written as,
LOCK
LW (R1),R2
ADD 1,R2
SW R2,(R1)Such an instruction sequence could easily form the basis of a semaphore implementation.
A similar instruction sequence known as a test and set can be written as,
LDI 1,R3
LOCK
LW (R1),R2
TEST R2
SW.Z R3,(R1)This operation reads a value from memory, checks to see if it is zero, and then
writes a one to the memory if it is. This sequence is useful for seeing if
a resource is available, and then marking it as in use if it is. The register
R2 can then be checked to know if the resource was available. Even better,
the result of this comparison has been conveniently left in the condition codes.
This is about as simple as it gets.
The actual implementation of this sequence is fairly simple as well–when implemented in Wishbone. Indeed, Wishbone exclusive access is quite easy: just hold the CYC line high between the load and the subsequent store, and nothing else will have access to that resource.
The ZipCPU
goes a bit further in its implementation: it guarantees that the
lock sequence will not be interrupted. Therefore, even if the lock sequence
is executed from user mode (with interrupts enabled), the LOCK instruction
disables interrupts for the three instructions following.
This makes atomic memory access simple when using the ZipCPU: the instruction sequence is simplified, and the Wishbone interaction necessary to support it is also quite simple.
Mapping this simplicity into AXI4 was not nearly so easy.
AXI4 atomic access semantics are quite different. AXI4, for example, doesn’t allow you to lock the bus and keep other users from accessing memory (for example) during your operation. Instead, AXI4 implements something called exclusive access. Exclusive access operations are described via a sequence of operations:
-
First, the CPU issues an exclusive access read. This is a read request (a load instruction) from the CPU where
ARLOCKis set. When the slave sees this request, it copies down the details of the request and returnsRRESP=EXOKAYwhen returning the request.If the slave doesn’t support exclusive access requests, then it simply processes the read as normal and returns
RRESP=OKAY. -
If the slave observes any subsequent writes to this address, it will invalidate this lock. Similarly, if the slave receives a subsequent read request with
ARLOCKset, the lock will move to a different address.On its face, this forces the slave to track one exclusive access address for every AxID value that it supports. Alternatively, the slave can monitor a single address and then keep track of the AxID of the last exclusive access request together with the address details of the request.
-
Some time after the exclusive access read request, the CPU will issue the subsequent write request. This request must match the read request: same address, same
AxLEN, sameAxSIZE, sameAxBURST, etc. The slave will then compare these values to the values given by the last exclusive access read request.-
If the values match and nothing has been written to that address since the read, then the request succeeds and the value is written to memory. This would be the case if nothing else had written to this memory since the previous exclusive access read. In this case, the slave returns
BRESP=EXOKAYto let the bus master know that the operation has been successful. -
Alternatively, if the 1) values don’t match or 2) if something has written to one of the addresses in the burst since the read, then the exclusive access write request fails. The slave then returns
BRESP=OKAYand doesn’t update any memory.
-
-
The next step takes place in the CPU. When the CPU sees the
BRESP=OKAY, rather than aBRESP=EXOKAYresponse, then it needs to repeat the exclusive access request again and again until it succeeds.
Now, how should the ZipCPU be modified to handle exclusive access?
A look at both ARM and Microblaze architectures didn’t help. These architectures both require an instruction sequence that’s closer tied to the hardware than the ZipCPU’s ISA allowed. First, they require special exclusive access load and store instructions. Following the exclusive access store instruction, the CPU must then check an internal register flag to see if the operation was successful, and branch if it was not.
DMB ish ; Memory barrier
loop:
LDREX R2,[R3] ; Load w/ exclusive access
ADD R0,R2,R1 ; An atomic add, R0 <= R2 + R1
STREX R12,R0,[R3] ; Store the result, R0, with exclusive access
CMP R12,#0 ; Check for the EXOKAY flag in R12
BNE loop ; Loop if the STREX didn't return EXOKAY
DMB ish ; Memory barrierThis requires both a longer instruction sequence, but also a more complex instruction decoder and hence a larger bit field for the relevant opcode.
This was unacceptable for me: I wanted to keep the ZipCPU simple. For that reason, I didn’t want to add any more instructions to the ZipCPU’s instruction set, nor did I want to support a different instruction sequence, additional special registers, or special register fields.
This lead me to design a solution based upon the state diagram in Fig. 2 below.
 |
Here’s how it works in detail:
-
When issued, the
LOCKinstruction would send its instruction address to the memory unit. -
The load instruction would be implemented as one might expect. Indeed, issuing the read is identical to the previous controller, save for a couple details–such as setting
ARLOCKand so forth.ARLOCKwould be set, etc. -
The first change comes if the load instruction does not return
RRESP=EXOKAY. The AXI4 specification says that the master may treat this as an error condition.
 |
When I first read this, I understood that the slave must return RRESP=OKAY
if it doesn’t support exclusive access operations, but otherwise the answer
wasn’t constrained. My first slave implementation, therefore, would return
RRESP=OKAY if the slave supported exclusive access but a current write
in progress would prevent this exclusive access operation from succeeding.
Hence, I would only return RRESP=EXOKAY if the operation was going to
succeed.
Upon further review, this initial AXI4 slave implementation was broken.
Practically, the slave must return EXOKAY if an exclusive access
operation might ever succeed for the given address.
The problem comes into play when you try to answer the question of what
the CPU should do on an RRESP=OKAY response. If the CPU doesn’t treat
RRESP=OKAY as an error,
then it will get stuck in an endless loop!
Hence, a request for exclusive access that returns RRESP=OKAY must
generate a bus
error return to the CPU.
-
On the other hand, if the CPU receives
RRESP=EXOKAYthen things proceed as before: the value from memory is returned to the CPU, written into the CPU’s register set, and then the CPU performs the ALU operation on the memory value. -
The store instruction then starts out as expected as well:
AWLOCKis set, and the write request is issued. -
The next change takes place while the store operation is ongoing: during this time, the CPU must stall to wait and see what the result of this operation will be. It cannot be allowed to continue with further instructions since they might need to be rolled back if the write ever failed. While some CPU’s might be able to undo or “roll-back” any following instructions, the ZipCPU has no such ability–hence, it cannot continue until this operation finishes successfully.
For this reason, the memory controller must signal a stall to the CPU.
In order to keep from rewriting any more of my memory interface than necessary, I abused the read-in-progress signal,
o_rdbusy, for this purpose. Hence, while an exclusive write operation is ongoing, the CPU is told that a read is in progress. This prevents the CPU from continuing, lest it attempt to perform an operation on a register whose value is yet to be returned from the read request.The second interface change is that, during this time, additional memory operations are disallowed by the memory controller. Only one outstanding write operation is allowed during an exclusive access write of any type. While this doesn’t really impact the axiops controller we are discussing today, it does have a bit of an impact on the pipelined memory controller by prohibiting the pipeline from every becoming more than a single write deep when using an exclusive access write.
-
If the exclusive access store completes with
BRESP=EXOKAY, the stalls outlined above are quietly released and the CPU continues as before. -
On the other hand, if the exclusive store completes with
BRESP=OKAY, then the memory controller returns a value to the CPU–much like it might return a value from a read instruction. The value returned is the value of theLOCKinstruction’s address, and this value is then written to the program counter. Yes, the ZipCPU’s instruction set allows loads directly to the program counter. This just forces the exclusive access store operation to masquerade as such a read on failure.
At least, that was the plan I decided on to make this work. I specifically
liked the fact that this plan didn’t require any changes to the instruction
set,
nor to the instruction decoder. Indeed, the only change required to the
CPU’s core,
that of passing the program
counter of the LOCK
instruction, was an easy/minor change to make.
Let’s therefore take a peek at how these details might be implemented in the memory controller.
The first step is to set the AxLOCK flag on any lock request. We’ll start
by clearing this value if either the memory controller doesn’t support
exclusive accesses or if the value is reset.
initial axlock = 1'b0;
always @(posedge i_clk)
if (!OPT_LOCK || (!S_AXI_ARESETN && OPT_LOWPOWER))
begin
axlock <= 1'b0;The next step takes place only if BREADY || RREADY.
end else if (M_AXI_BREADY || M_AXI_RREADY)
begin // Something is outstanding
if (OPT_LOWPOWER && (M_AXI_BVALID || M_AXI_RVALID))
axlock <= axlock && i_lock && M_AXI_RVALID;As a point of reference from our last
article, the BREADY
and RREADY flags are being used as part of an implicit state machine to tell
us if an operation is ongoing. BREADY, therefore, is only set if a write
operation is ongoing. Likewise RREADY is only set if a read operation is
ongoing. For this reason, the BREADY || RREADY check above is our way of
testing if an operation is ongoing.
If an operation is ongoing then we really don’t need to change anything. However, if we’re trying to keep our power down, then it might make sense to clear the lock flag at the end of the exclusive access write operation.
Otherwise, if there’s no operation ongoing, then we’ll want to set the
lock flag on any incoming memory request. Here, again, we split the logic
into two possibilities: if we don’t care about arbitrarily toggling this
value, that is if OPT_LOWPOWER isn’t set and we are optimizing for low
area, then we just set axlock based upon the CPU’s lock request independent
of whether or not a new request is being made.
end else begin // New memory operation
// Initiate a request
if (!OPT_LOWPOWER)
axlock <= i_lock;
else beginIf OPT_LOWPOWER is set, then we are going to try to minimize the number of
times anything toggles, including axlock.
Therefore we’ll set axlock on any new memory request arriving
with the lock flag set, but otherwise clear the flag if an incoming lock
request will not result in an outgoing request.
if (i_stb)
axlock <= i_lock;
if (i_cpu_reset || o_err || w_misaligned)
axlock <= 1'b0;
end
end
assign M_AXI_AWLOCK = axlock;
assign M_AXI_ARLOCK = axlock;This signal is then used to set the AXI AWLOCK and ARLOCK signals.
One of the AXI rules about exclusive access requests, however, is that all
exclusive access requests must be aligned. It is a
bus protocol violation to
issue an exclusive access request for an unaligned address. Hence, we’ll need
to return a bus
error
to the CPU on any request for exclusive access to an unaligned memory address.
This is controlled by the w_misalignment_err flag below.
Normally, this w_misalignment_err flag is set on any unaligned access if the
CPU is configured to generate a
bus
error on any unaligned request.
always @(*)
begin
// Return an error if a request requires two beats and we
// don't support breaking the request into two, or ...
w_misalignment_err = OPT_ALIGNMENT_ERR && w_misaligned;To that logic, we add the exclusive access check for an unaligned access.
if (OPT_LOCK && i_lock)
begin
// Return an error on any lock request for an unaligned
// address--no matter how it is unaligned.
casez(i_op[2:1])
2'b0?: w_misalignment_err = (|i_addr[1:0]);
2'b10: w_misalignment_err = i_addr[0];
default:
w_misalignment_err = 1'b0;
endcase
end
endWhile the bus
operation is ongoing, the memory controller must tell the
CPU that it is busy with the request. This is done via the “read-busy”
signal, o_rdbusy. We’d nominally set this flag if RREADY were true,
indicating that a read operation was ongoing, with the exception being if the
CPU ever needed to flush pending responses from the
bus–such
as if the CPU had received a reset independent of a
bus reset, or following a
bus
error of any type.
o_rdbusy = M_AXI_RREADY && !r_flushing;This r_flushing signal
is one of the biggest differences between the
Wishbone memory
controller and the
AXI controller:
AXI doesn’t allow bus
aborts. Hence, if a transaction is ongoing when the
CPU is reset, or likewise if a transaction is ongoing when an
error condition is received, then
the CPU wants to abort any outstanding transactions. Since AXI doesn’t have a
bus
abort capability, we’ll instead flush the returns. That is, we count how
many requests are outstanding, and then wait for this value to return to zero
before returning back to operation again.
Keep in mind, this o_rdbusy signal is different from the busy signal,
o_busy. If o_busy is true, the memory controller won’t accept any new
requests, and it won’t switch from user to supervisor
mode–choosing instead
to wait until all requests are complete. If o_rdbusy is true, on the other
hand, then the CPU must also stall and wait on a read return.
That was before AXI exclusive access support.
Now we need to declare ourselves busy during exclusive access writes as well.
o_rdbusy = (M_AXI_BREADY && axlock) || M_AXI_RREADY;
if (r_flushing)
o_rdbusy = 1'b0;That’s because we might need to write to the
program counter register once
the exclusive access store instruction completes, assuming it didn’t receive
BRESP=EXOKAY, just like a normal read might. This then forces the CPU to
stall waiting on the end of the exclusive access write, whereas it might
otherwise have continued onto its next instruction even though a write
operation might have been outstanding.
Once the exclusive access operation completes, we’ll need to either raise
o_valid, to indicate a read has completed and the result is to be written
to a CPU register (such as the program
counter), or o_err to
cause the CPU to recognize a
bus
error and trap, or neither if
the write completes successfully.
The semantics for o_valid are a touch different
from before.
Before we’d return
o_valid once any read operation completed to indicate that a read result
was ready to be copied into a CPU register. Now, when using exclusive access,
we’ll also need to declare a successful read result if the write operation
failed. Remember, if the write operation fails to receive BRESP=EXOKAY then
we need to write a new program
counter
value to the CPU and cause it to jump to the beginning of the LOCK operation
to repeat it–hence we need to set o_valid in that case to indicate a valid
read return.
else if (axlock)
o_valid <= (M_AXI_RVALID && M_AXI_RRESP == EXOKAY)
|| (M_AXI_BVALID && M_AXI_BRESP == OKAY);Finally, during an exclusive access sequence we’ll need to generate an error
return on any bus
error we receive. Likewise, if an
exclusive access read return is anything other than EXOKAY then we’ll
also return an error.
else if (axlock)
begin
o_err <= (M_AXI_BVALID && M_AXI_BRESP[1])
|| (M_AXI_RVALID && M_AXI_RRESP != EXOKAY);Such errors will force the CPU to have an exception. If the ZipCPU is in user mode, it will simply set an bus error exception flag and switch to supervisor mode. If the ZipCPU is in supervisor mode, however, it will either 1) halt on an exception for the debugger, or 2) reboot–depending on how it was configured at build time.
Note that if the write operation completes successfully with BRESP=EXOKAY,
then o_rdbusy will quietly be dropped without setting either o_valid or
o_err.
That leaves three final parts to the exclusive access implementation: the return register, and two pieces of logic required for the return register’s value.
Normally, the memory controller keeps track of the return register on any read, so the CPU can be told where to write the read result back to.
always @(posedge i_clk)
if (i_stb)
o_wreg <= i_oreg;The need for this interface is driven by the pipelined memory
controller’s
implementation, where this value is kept in a FIFO. In the case of today’s
simplified controller,
we simply keep track of which CPU register to write the return into in o_wreg.
When using exclusive access, we also want the CPU to execute a jump to the
original LOCK instruction on a failed write return. Hence, on any exclusive
access write request, we set the return CPU register index to be the
program counter’s register
index. In the case of the ZipCPU,
the bottom four bits of the program counter’s index is
15 leading to the logic
listed below.
if (i_stb)
begin
o_wreg <= i_oreg;
if (OPT_LOCK && i_stb && i_lock && i_op[0])
o_wreg[3:0] <= 4'hf;
endThe last exclusive access change is to keep track of the address to restart
from on a write failure. For this, we’ll first introduce a new register:
r_pc. On the first load, as the exclusive access sequence begins, we’ll
record the address of the initial LOCK instruction given to the memory
controller by the CPU.
always @(posedge S_AXI_ACLK)
if (!OPT_LOCK)
r_pc <= 0;
else if (i_stb && i_lock && !i_op[0])
r_pc <= i_restart_pc;The next step is to determine the return value to be returned to the CPU.
Nominally, this return value would simply be RDATA. The logic below,
however, is just a touch more complex.
First, we’ll zero the return value if OPT_LOWPOWER is set and there won’t
be any return.
always @(posedge i_clk)
if (OPT_LOWPOWER &&((!M_AXI_RREADY && (!OPT_LOCK || !M_AXI_BREADY))
|| !S_AXI_ARESETN || r_flushing || i_cpu_reset))
o_result <= 0;
else beginMore interesting is what we do on a write return. On any exclusive access
write return failure, where BRESP == OKAY rather then EXOKAY, o_result
is set to the program counter
value captured above in r_pc.
if (OPT_LOCK && M_AXI_BVALID && (!OPT_LOWPOWER
|| (axlock && M_AXI_BRESP == OKAY)))
begin
o_result <= 0;
o_result[AW-1:0] <= r_pc;
endThe rest of the read return logic is only activated on an actual read return. It’s the same logic that we originally presented, so we’ll skip the details here.
if (M_AXI_RVALID)
// ...
endThe big lesson to be learned here, regarding how to implement an exclusive access sequence, is that the sequence is really a state machine. Fig. 4 below shows the basic four-state machine controlling an exclusive access request.
 |
Once you realize that it’s just a basic state machine, verification gets easy. Indeed, my own verification properties simply tie assertions (and assumptions) to the various states of this machine, as shown below.
 |
That leads us to the next big change going from AXI-lite to AXI: the AxSIZE field.
Updating AxSIZE
On its surface, the AxSIZE field should be fairly simple. If the CPU wants to
write a byte to or read a byte from memory, then the size should be 3'b000
(one byte). If the transaction calls for two bytes of memory, then the size
should be 3'b001 (16’bit word), and if the transaction calls for four bytes
of memory then the size should be 3'b010 (32’bit word). This only makes
sense.
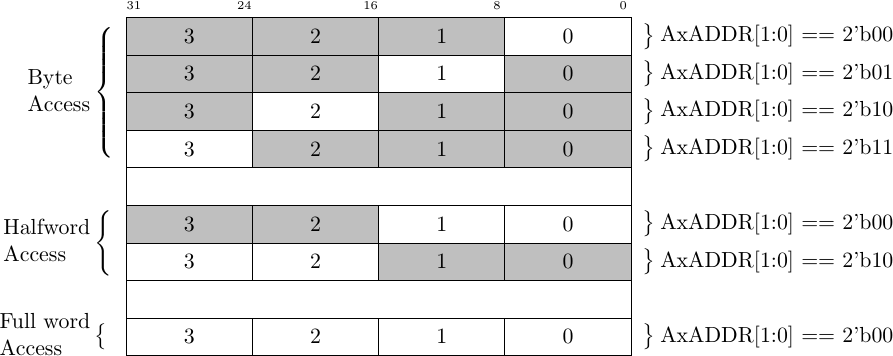 |
Sadly, the formal tool found several problems with this “only makes sense” design.
The first problem was my own fault. Once I got the design to work, I then wanted to add “features”. The feature that triggered this problem was the unaligned feature, not shown in Fig. 6 above. Handling an unaligned request requires (potentially) turning a single request to write a 2-byte or 4-byte word into multiple 32-bit transactions.
Fig. 7 below shows three examples of how an unaligned 32-bit access can be spread across two separate but successive AXI4 beats.
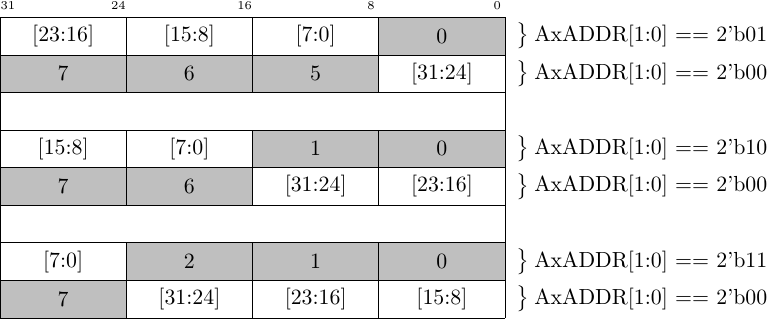 |
The second problem was my desire to make the design bus width independent. In the past, I’ve seen memory requests to/from a 64-bit memory get wasted by only issuing 32-bit commands to the bus at a time. If I just made the memory controller in such a way that the bus width could be parameterized, then I might get some more efficiency from my memory controller.
At this point, I might not have noticed any problems save that I had recently built a bus downsizer–a bridge to transition a bus from one width to a smaller width. This bridge breaks an AXI4 request into (potentially) multiple requests. Knowing where each request begins and how many requests to issue, however, depends upon the AxSIZE parameter.
Remembering how this downsizer worked forced me to look a bit deeper at how AxSIZE might be set.
As an example, let’s suppose we have a bus width of 64-bits that needs to be reduced to 32-bits. In this case, if AxSIZE indicates that the transaction is 64 bits wide and the AxADDR field indicates that the first 32-bits of the transaction will be used, then the downsizer will transform the transaction into two 32-bit transactions–each requiring one clock per request and one clock per return.
Fig. 8 shows two examples of this. In the first example, the bus word needs to be broken into two 32-bit accesses. In the second example, a single 32-bit access is sufficient.
| Original transaction on a 64-bit Bus | Same transaction, after downsizing to 32-bits |
|---|---|
| Word size transaction, starting at AxAddr[1:0] == 3, requires two beats on a 32-bit bus | |
 |  |
| Halfword transaction, starting at AxAddr[2:0] == 5, downsizes to a single beat on a 32-bit bus | |
 |  |
On the other hand, if AxSIZE either indicates that any transaction has only 32-bits or equivalently if the AxADDR indicates that only the upper 32-bits will be impacted, then the downsizer will only transform the transaction into a single 32-bit transaction. In other words, there is efficiency to be had by keeping the transaction size specified in AxSIZE as small as possible.
This problem is only compounded the larger the size difference is between the two buses. For example, if the first bus is 64-bits but the smaller bus is only 8-bits, then the downsizer might have to break the request up into eight smaller transactions–but, again, this all depends upon both AxSIZE and AxADDR.
So, how did this work out?
Well, I first built the logic below–much as I indicated above.
// CPU_DATA_WIDTH for the ZipCPU is always 32-bits--independent
// of the final bus size. The final bus size must be at least
// 32-bits, but may be arbitrarily larger.
localparam [2:0] DSZ = $clog2(CPU_DATA_WIDTH/8);
initial axsize = DSZ;
always @(posedge i_clk)
if (!S_AXI_ARESETN)
axsize <= DSZ;
else if (!M_AXI_BREADY && !M_AXI_RREADY)
begin
casez(i_op[2:1])
2'b0?: axsize <= 3'b010; // Word
2'b10: axsize <= 3'b001; // Half-word
2'b11: axsize <= 3'b000; // Byte
endcase
end
assign M_AXI_AWSIZE = axsize;
assign M_AXI_ARSIZE = axsize;This worked great–up until I tried to enable misaligned transactions. When I did that, I came across the transaction shown below in Fig. 9.
 |
Was this transaction legal?
On the one hand, its a two-byte transaction bound to two bytes, therefore it looks legal. On the other hand, if this were a burst transaction, the second beat would necessarily start at address two–breaking the word in two, so that two separate beats would be writing to the same word.
That didn’t make sense.
So, I did some digging. I discovered a discrepancy between the AXI4 standard I was using and the more recent AXI4 standards when it came to determining the second address in a burst. The second address of a burst is always the next aligned address, given the alignment specified by AxSIZE.
That was enough for me. I now marked this transaction as an illegal transaction, adjusted my formal properties to handle it, and then went back to adjusting the CPU again to handle it. Thankfully, I could quickly reverify all of my AXI designs against this updated standard and nothing failed–save the ZipCPU’s new AXI memory controllers.
It was now time to come back and try to get the AxSIZE field right again–this time with some more explicit formal properties.
My second approach, therefore, was to simply expand the transaction size if I ever noticed an unaligned transaction. In this approach, I thought I might just merge the two halfwords together, and split any unaligned word requests into two beats.
// ...
casez(i_op[2:1])
2'b0?: begin
axsize <= 3'b010; // Word
if (|i_addr[1:0])
axsize <= 3'b010; // Split into two beats
end
2'b10: begin
axsize <= 3'b001; // Half-word
if (i_addr[0])
axsize <= 3'b010; // Expand to 32-bit size
end
2'b11: axsize <= 3'b000; // Byte
endcase
// ...Here, I noticed three things.
-
Byte requests can never be misaligned. Their size can always be
3'b000, and they’ll never trigger a misaligned request requiring two beats. -
Expanding the transaction to two 32’bit words works great, but only on a 32-bit bus. On a 64-bit bus, we might still be able to keep the two transactions in a single beat.
It’s worse than might, however, since my read/write logic depends upon transactions taking two beats being split over two bus-sized words.
This means that, if the transaction could at all fit into a single bus word, then it needed to be placed into a single bus word.
-
There’s another problem as well: the halfword transaction might also need to be split into two beats. Just expanding it to two bytes isn’t sufficient if the two bytes won’t fit in the bus word.
My next approach was then to try merging requests into a single bus word where possible.
casez(i_op[2:1])
2'b0?: begin
axsize <= 3'b010; // Word
if ((|i_addr[1:0]) && !w_misaligned)
axsize <= 3'b011; // 64-bit width
end
2'b10: begin
axsize <= 3'b001; // Half-word
if (i_addr[0])
axsize <= 3'b010; // 32-bit width
endIn this approach, I use the flag w_misaligned. This flag is intended to
capture whether or not the request needs to be split into two beats. Hence,
if the request doesn’t need to be split, then I simply keep the original
width.
Unfortunately, this doesn’t work either. What happens if a half-word transaction needs to cross over two 32-bit fields on the 64-bit bus? Similarly, what would happen if a word size transaction needed to cross two 64-bit fields on a 128-bit bus?
 |
Frankly, I never would’ve thought of this if I hadn’t adjusted my formal properties earlier. Unfortunately, this led to a very complex calculation of AxSIZE based on the size of the transaction and how far off the transaction would be, as shown in Fig. 11 below.
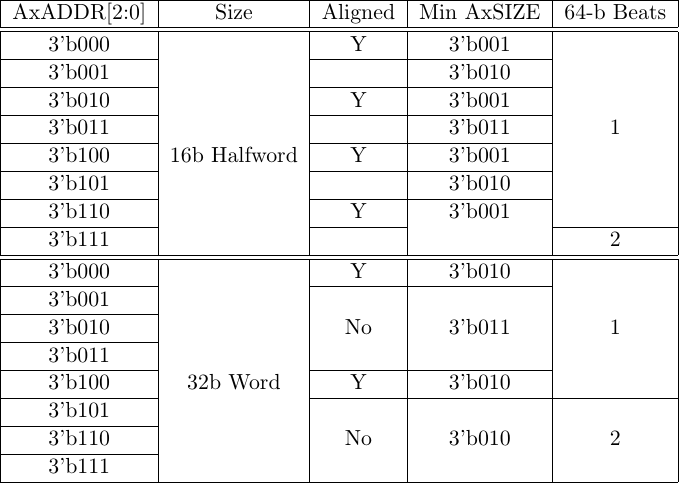 |
At this point, I gave up and just tried to simplify things as much as possible. It’s not that the logic required to implement the table was too complex, but rather it was becoming too complex to be generic across all bus sizes. The one guaranteed solution to this problem was to simply bump the AxSIZE value up from the minimum required size to that of a full bus word if the request was ever misaligned and was not going to be broken into two words. If the request was going to be broken into two words, it could still keep its original size since each word would (of necessity) contain fewer bytes than the original size would require.
This led me to the following logic.
localparam AXILSB = $clog2(C_AXI_DATA_WIDTH/8);
localparam DSZ = $clog2(32/8);
// M_AXI_AxSIZE
reg [2:0] axsize;
initial axsize = DSZ;
always @(posedge i_clk)
if (!S_AXI_ARESETN)
axsize <= DSZ;
else if (!M_AXI_BREADY && !M_AXI_RREADY && (!OPT_LOWPOWER || i_stb))Let me stop here, for a moment, because I just added a new requirement to
the logic we’ve been building: !OPT_LOWPOWER || i_stb. As I mentioned
when discussing exclusive access above, the OPT_LOWPOWER parameter is
part of my ongoing effort to build logic that can work in both low power
environments and low logic environments. In general, I force things to
zero on low power. Here, I simply only allow the AxSIZE parameter to
change on a bus request
(i.e. i_stb), or I simplify the logic if I don’t care about low power and
allow it to change any time for the savings of a LUT or two.
begin
casez(i_op[2:1])
2'b0?: begin
axsize <= 3'b010; // Word
if ((|i_addr[1:0]) && !w_misaligned)
axsize <= AXILSB[2:0];
end
2'b10: begin
axsize <= 3'b001; // Half-word
if (i_addr[0] && !w_misaligned)
axsize <= AXILSB[2:0];
end
2'b11: axsize <= 3'b000; // Byte
endcaseThere is, however, one exception to the AxSIZE rule and that exception is if the CPU is running big-endian software. Remember, the AXI4 bus is by nature little endian, and the ZipCPU tool chain is big endian. Adjusting the CPU to make the ZipCPU little endian is actually quite easy to do–that’s not a problem at all. Adjusting the tool chain (GAS, GCC, C-Lib)? That takes more work. As a result, I’m running the ZipCPU in a big endian configuration on a little endian bus. The result has been more than a hassle.
This also means that, when writing to the bus, the address requested doesn’t necessarily correspond with the bus address. For example, writing a halfword to address 0 (big endian) means that it writes to address 2 (little endian). Part of my solution has been to clip all address requests so that they are aligned and just move the words/bytes into place as necessary. That also forces the size parameter to always reference the full size of the bus, as shown below.
if (SWAP_WSTRB) // CPU is running big-endian
axsize <= DSZ;
end
assign M_AXI_AWSIZE = axsize;
assign M_AXI_ARSIZE = M_AXI_AWSIZE;No, this big vs little endian “solution” does not follow the recommendations of the AXI4 specification, but it 1) works, and 2) was easier to do than adjusting every other slave my my design as the AXI specification requires.
The logic above is now my current solution to setting AxSIZE. It’s not elegant, but it works and it keeps with the low logic spirit of the ZipCPU.
Two unused features: AxLEN and AxID
The two AXI features this design doesn’t use are the AxLEN and AxID fields. Let me explain why, starting with the AxID field.
AxID is perhaps best known for its out of order feature. If two packets are requested, whether they be reads or writes, if their AxID’s are different then their returns may come back out of order. If their AxID’s are the same, however, the requests must come back in the order they were issued. This feature helps to create multiple virtual channels through the AXI interconnect. It can also be a real challenge when it comes to formally verifying a design–but that’s another story.
 |
Handling AxIDs is fairly easy within a slave: the slave just needs to return the requests given to it with the AxIDs provided. This is called mirroring, and its fairly easy to do: incoming requests just go into a FIFO having the depth of the slave’s pipeline. Upon return, the request is simply returned with the ARID provided with the request. It’s that simple.
 |
Where AxIDs become difficult to handle is within the interconnect. The interconnect must guarantee that any two packets with the same AxID are always returned in order. This creates some derived requirements within the interconnect: The first is that the interconnect cannot switch arbitration from a given master, ID, slave combination to another slave until all of the returns have been received for the first master, ID, and slave combination. This forces the interconnect to contain a counter for every master, ID pair to count the number of requests made minus responses received. Only when the counter indicates there are no outstanding requests for a given master, ID pair, is the interconnect allowed to reallocate that channel to a new slave. A second derived requirement is that the interconnect must stall the upstream master before its counter ever overruns.
 |
These aren’t problems within the source–that is within the original AXI4 master. In any given source, such as within a CPU, there’s a bit of a different purpose for AxIDs. Inside the source, each different master can be assigned a different and unique ID. For example, the instruction fetch can be given one ID and the memory controller another, as illustrated in Fig. 14 on the right. In a scatter gather DMA, the table reader could be given one ID and the underlying DMA another. In both cases, the master/source is simplified by only issuing requests to and receiving responses from a single ID. This is also what we’ll do here: we’ll assign a fixed ID to the memory controller. This will also simplify our logic. By using a single ID, 1) we can verify the AXI interface against a single ID channel. Further, we can also 2) ignore the RID and BID returns knowing that we’ll never get a return for an ID we haven’t requested.
That handles the AxID field: it’s just a constant.
parameter AXI_ID = 0;
// ...
assign M_AXI_AWID = AXI_ID;
assign M_AXI_ARID = AXI_ID;But what about AxLEN?
Just for background, the AxLEN field is used to indicate that the AXI4 bus master wants to issue a burst request of (AxLEN+1) beats. Both the interconnect and the ultimate slave can then use this value to optimize the transaction–knowing that more beats are coming from a given request.
This is another feature we won’t use. This is also a feature that confuses a lot of CPU users, leading to a common question: Why isn’t the CPU (Microblaze, ARM, etc.) issuing burst requests of the FPGA?
For this, let me offer several observations.
- The CPU never knows how many accesses will be made of the bus.
What of the case of a memcpy() library call, however, where the CPU knows
that a lot of data needs to be moved? Can’t a burst instruction be used
there?
The answer here, again, is no. Remember, a CPU will only ever execute one instruction at a time. Even dual issue CPUs are designed to maintain the appearance of only ever issuing one instruction at a time. To illustrate how this affects things, consider the following (super-simplified) memory move routine in ZipCPU assembly:
_simple_memcpy: // R1=DST, R2=SRC, R3=LEN
CMP 0,R3 // Return immediately on a zero length copy
RTN.Z
_move_loop:
LW (R2),R4 // Read from the source
SW R4,(R1) // Write the value to the destination
ADD 4,R2 // Update the source pointer
ADD 4,R1 // Update destination pointer
SUB 1,R3 // Update the remaining length
BNZ _move_loop // Repeat if more remains to copy
RTN // All done, returnNow, looking through this, remember that the hardware only ever sees one instruction of this sequence at any given time. Nowhere in this instruction sequence is there an instruction to indicate a burst transaction of more than one beat. Worse, never in the CPU pipeline will it see two loads or two stores in a row.
 |
Keep in mind, this is a very simplified memory copy example. A real memory copy can be much more complex. For example, in this simplified example we’ve assumed that the two pointers are aligned on a word boundary (32bits for the ZipCPU), and that the length is specified in a number of words. Similarly, there are some optimizations that could be made to this function. For example, if we could verify that the number of words to be copied would be greater than one each time through the loop, then we might manage to pipeline the memory copy to issue more than one load (or store) at a time–but that’s still not a burst operation for the same reason: nowhere in this set of instructions does the CPU hardware get told how much memory the software wishes to copy.
In other words, the nature of a CPU simply leaves us out of luck here.
-
A data cache is only subtly different. In the case of a data cache, and even then only when reading from memory, you can read more data than you need. Indeed, you can read an entire cache line at a time. This allows you to use burst reads nicely to your advantage. The problem here, however, is that you can only issue burst read requests of memory. If you make a mistake and issue a burst read of a memory mapped peripheral, such as the serial port’s data FIFO, then you might invoke a side effect you aren’t intending–such as accidentally clearing the unread data from the serial port when just trying to read how much data is available in that FIFO.
-
There is one potential place in this design where we might use an AXI burst, and that’s when reading (or writing) to an unaligned address. As an example, suppose we wished to write 4 bytes to address 1. Such a request would either need to cause a bus error, due to the unaligned request, or else 2) it would need to be broken into two requests. If the request was broken into two adjacent requests as illustrated in Fig. 7 above, then it might make sense to use AxLEN=1.
The problem with this choice is that AXI has a requirement that burst requests may not cross 4kB boundaries. That means that, in order to turn an unaligned request into a two beat burst, the CPU would need extra logic to use singleton requests anytime the 4kB boundary were being crossed but burst requests at other times.
If it costs all that work, why not just issue a pair of singleton requests in the first place? I mean, you need to build that logic into the memory controller anyway to handle the 4kB boundary crossing!
Now, let’s add to this discussion my own background with a stripped down Wishbone. Wishbone, as I use it, has no capability for burst requests like AXI. This has not slowed down either my interconnect implementations or my slave implementations. If necessary, a slave can just take a peek at the next request address to derive any details of a burst as it arrives.
 |
As a result, this non-cached memory
controller
leaves AxLEN==0.
My AXI4 data cache implementation?
That’s the one example I have where ARLEN may be set to something greater
than zero.
In that case, however, 1) the cache
implementation
offers no support for unaligned requests, and 2) the data
cache
needs to separate memory requests from peripheral
requests.
Memory requests can be cached, and they get burst read support. Yes, that’s
right, the cache
only provides burst read support, there’s no burst write support–since
the ZipCPU’s AXI4 data
cache
is a write-through cache. Writes go directly to the
bus
as outlined above. Peripheral requests also fundamentally use the
same logic we’ve just outlined above as well.
Remaining signals
These leaves only a small number of remaining signals: AxBURST, WLAST, AxQOS, and AxCACHE.
I’ve set M_AXI_AWBURST to 2'b01, also known as INCR(ement).
It could’ve just as easily been set to 2'b00 for a FIXED address burst
since we’re only issuing singleton requests.
localparam [1:0] AXI_INCR = 2'b01;
assign M_AXI_AWBURST = AXI_INCR;
assign M_AXI_ARBURST = AXI_INCR;Similarly, since we’re not using bursts, I can also set WLAST to one.
assign M_AXI_WLAST = 1;What about AxQOS? Frankly, this seems to me like a feature of an over designed, overly complex bus structure. I have only a small number of designs that have even implemented QOS. It’s a challenge to implement, so I’ve really only used it in arbiters to help arbitration. Even at that, the four bit comparison in addition to the arbitration can be a hassle to accomplish, so most of my designs ignore it.
In this case, I simply set it to a fixed constant, zero, but one that can be adjusted when the design is built if necessary.
parameter [3:0] OPT_QOS = 0;
assign M_AXI_AWQOS = OPT_QOS;
assign M_AXI_ARQOS = OPT_QOS;I also do the same thing with AxPROT. The difference here is that AxPROT[0]
must be zero to indicate that this is a data access. As for the other bits,
secure/non-secure or privileged vs non-privileged, I have yet to find a good
description/reference for what those refer to. For the time being, therefore,
I’m leaving these bits at zero.
localparam [2:0] AXI_UNPRIVILEGED_NONSECURE_DATA_ACCESS = 3'h0;
localparam [2:0] OPT_PROT=AXI_UNPRIVILEGED_NONSECURE_DATA_ACCESS;
assign M_AXI_AWQOS = OPT_PROT;
assign M_AXI_ARQOS = OPT_PROT;That leaves AxCACHE. Here again is a signal for which … I’m not sure what
the right answer is. The AXI4
specification just leaves me confused.
What I do know is that Xilinx recommends an AxCACHE value of 4'h3
(normal, non-cacheable, bufferable). On the other hand, I want to make sure
any lock requests make it all the way to the device. Therefore, I set
AxCACHE to zero for lock requests–forcing any exclusive access request
to go through any intermediate caching all the way to the device.
localparam [3:0] AXI_NON_CACHABLE_BUFFERABLE = 4'h3;
localparam [3:0] AXI_DEVICE_NON_BUFFERABLE = 4'h0;
assign M_AXI_AWCACHE = M_AXI_AWLOCK ? AXI_DEVICE_NON_BUFFERABLE
: AXI_NON_CACHABLE_BUFFERABLE;
assign M_AXI_ARCACHE = M_AXI_ARLOCK ? AXI_DEVICE_NON_BUFFERABLE
: AXI_NON_CACHABLE_BUFFERABLE;You may notice that a lot of these signals just maintain constant values. That’s a lot of what I’ve seen when working with AXI4: there are a lot of signals that just … don’t need to be there.
Conclusion
These are therefore the basic modifications necessary to convert an AXI4-lite
CPU memory controller
into a full AXI4 memory controller.
Perhaps the most important new feature is the support for
atomic
accesses via AXI’s exclusive access capability. Filling in the details of
the size, explaining why we’re not using AxLEN > 0, and the rest of the
(mostly unused) ports filled out the rest of our discussion.
This is not to say that all AXI4 memory controllers need to look like this one. Indeed, some of our choices only make sense in a minimum logic implementation, such as this one is intended to be. These include the choice to only issue one request at a time, as well as the choice not to cache any results. Lord willing and with enough interest, we’ll can come back at a later time and discuss improving upon this memory controller in one of these two fashions.
The problem, however, is that without exclusive access support in the slave it doesn’t matter whether or not the master (i.e. the CPU) supports it or not. Xilinx’s Memory Interface Generator (MIG) DDR3 SDRAM controller doesn’t support AXI exclusive access requests, nor does their block RAM controller. That means, for now, that if you want exclusive access support you’ll need a non-Xilinx memory controller.
To handle this need, I’ve converted my demonstration AXI4 slave to offer this support. You can see the changes required here. I’ve also got an SRAM controller with exclusive access support, based upon the same demo AXI slave, that I anticipate posting as well in the near future.
For now, the changes required to make exclusive access work in a slave will have to remain the topic of another article.
And if a man also strive for masteries, yet is he not crowned, except he strive lawfully. (2Tim 2:5)