
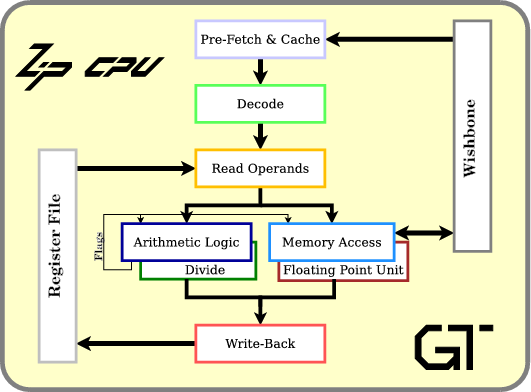
Pipelining a Prefetch
If you are familiar with the ZipCPU, you’ll know that it was built in order to be a fully capable CPU while only using a minimal amount of FPGA logic.
 |
There’s a problem, though, with the phrase, “minimal amount of logic.” Specifically, how much is minimal? This is a difficult question, since the answer changes from one design to the next. When it comes to a soft-core CPU, logic and performance start to trade off against each other as well. What I mean by that is that you can often spend logic within an FPGA in order to purchase better performance. Hence, if you want to build a fast CPU, you’ll want to use as much logic as you can to purchase that high speed. On the other hand, if you want to fit within a very small space, you might find that speed is not nearly as important.
As an example, this was the trade-off within the S6SoC. The S6SoC as you may recall is a demonstration of the ZipCPU that runs within a Spartan 6 LX4–the smallest Spartan 6 (S6) FPGA you could ever buy from Xilinx. Getting a multi-tasking CPU to fit within these constraints was a challenge. Getting that same CPU to have decent performance at the same time is even harder.
 |
Getting the ZipCPU to fit within the S6SoC took a bit of trimming. I got rid of the pipelining, switched to the lowest logic memory controller I knew how to build and the lowest logic prefetch. I removed the divide unit and removed early branching. (All of these modifications can be made from within the cpudefs.v file.) I got rid of the performance counters, the DMA engine, and the various timers that service the CPU. I even had to remove the debugging bus–there just wasn’t room on the LX4. With a bit of work, I managed to get this trimmed-down CPU to fit within the S6 on board Digilent’s CMod S6 board.
Then I tried to apply this
trimmed-down
CPU to an
audio application. Oh, it was a simple
demonstration: when the button is pressed, play a doorbell sound from a
recorded 8 kHz audio sample array.
The CPU wasn’t fast enough.
All the CPU had to do was to read the audio samples from flash memory, service interrupts, and particularly service the audio interrupt to write one sample at a time to the audio controller. (Remember, I had no room for the DMA engine to do this automatically.)
The CPU just wasn’t fast enough as built for even that.
Speeding up a CPU in an environment where every LUT matters can be a challenge.
The first thing I did was to move some of the CPU’s instructions from flash to block RAM. Since I didn’t have enough block RAM to do this for the whole multitasking “O/S”, I only put the critical components into the limited RAM.
That still wasn’t fast enough.
Then, in my last round with the S6SoC, I created a better prefetch unit I called dblfetch. This prefetch was low logic enough to fit within the space I had, but also faster than the simpler prefetch I had started with. This prefetch unit, or rather a slightly modified one, is also the subject of this article.
Measuring Memory Performance
Let’s start, though, by looking at how to measure memory performance. In a synchronous design, where everything takes place on a clock tick, then memory performance can be quantified by how many clocks it takes per transaction.
When using the B3 version
of the
wishbone bus, there’s
a fixed number of clocks for every transaction–we’ll call this the
transaction’s latency, L. Hence, if you want to access N memory locations,
this will cost you LN clocks.
 |
On the other hand, if you use the
pipelined
mode of the
wishbone bus
as illustrated in Fig 3 on the left
(version B4 only), you can then have
multiple transactions in flight at the same
time. In this case, the time it takes to accomplish a transaction becomes
(N-1)S+L. In other words, there’s an initial latency L, followed by a
number of clocks S for each additional transaction within the burst.
If you look at this from a purely peripheral perspective, you can see six separate peripheral implementations (approximately) outlined in the table below.
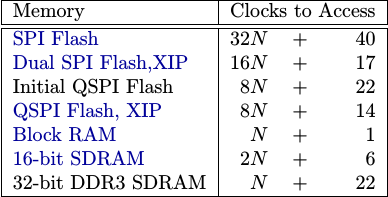 |
My initial controller for the QSPI flash on the S6SoC required 43-clocks for a single transaction. There was a delay or two within the logic of the CPU and the bus structure–we’ll say it was a two clock delay, with one clock on either side of the actual flash access (shown in blue below). Further, the non-pipelined version of the CPU at the time required 4 more clocks per instruction. The result was that it cost the CPU 49 clocks per instruction (CPI). With a 12ns clock, this meant that the ZipCPU could at best run 1.6 Million Instructions per Second (MIPS).
 |
At a rate of 1.6 MIPS I had 200 instructions to deal with each audio sample. These 200 instructions had handle everything else as well: interrupts, button presses, the software based real-time clock, etc. No wonder it couldn’t keep up with the 8kHz audio stream!
Of course, the real answer to making a CPU faster would be to pipeline the CPU and run with a proper prefetch and instruction cache–even better, to run the CPU from an on-board block RAM device. This approach would have the performance shown in Fig 5.
 |
If I only had the logic to do that, the ZipCPU would’ve ran close to one clock per instruction, once the cache was loaded, and would then achieve nearly 82 MIPS (minus cache stalls) on the Spartan 6. There just wasn’t enough logic in the LX4 to do this.
What else could be done?
If I placed the most common instructions into block RAM, as I discussed above, then the CPU could run at about 12 MIPS.
 |
Thanks to the author of the ECO32 CPU I was rather surprised to learn at the time that binutils supported this sort of dual addressing–with some addresses in flash, and other addresses in a section of RAM that had been copied/loaded from the flash–all controlled from a linker script.
This would’ve been perfect except the S6 LX4 just doesn’t have that much block RAM. I needed to run instructions from the flash.
In my case, there was more that could be done by trimming the flash controller.
To understand the options and possibilities, let’s back up for a moment and
discuss what the
QSPI flash protocol
requires.
After you give the
flash
a “Fast Read Quad Output” command (0xEBh), the
QSPI flash
I was working with would enter into an eXecute In Place (XIP) mode.
From this XIP mode,
any new instruction requires lowering the CS_n line, issuing an address,
then another byte indicating whether or not you wish to remain in XIP mode,
and then several dummy clocks. Only after all this setup could you then read
one 32-bit value from the
flash
every eight clocks.
Fig 7. below shows the clocks required in the setup.
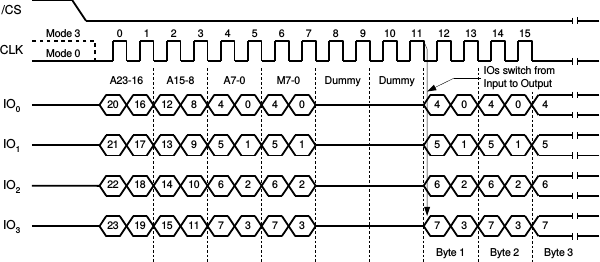 |
This is the fastest way to read from the flash, although it requires an SCK or two for setup and tear-down. Using this mode, it will take 80 QSPI bits, or equivalently 20 QSPI SCK’s, to read any arbitrary 32-bits of data from the flash.
One problem with my
flash design at the time was
that it was creating a SPI
clock from logic. On one clock cycle the SPI clock output would be a one,
then a zero, etc. As a result, the fastest SPI clock, SCK, I could create
was at half my system clock rate, or 41MHz.
If I instead switched from a logic generated clock to a clock generated by a
Xilinx
ODDR
primitive,
then the SPI clock SCK would transition on each clock edge and run at the
same speed as the design’s system clock speed (82 MHz).
By doubling the speed of the SPI SCK, I could then also double the speed of the
flash
to roughly 22-clocks per fetch, or 28 clocks per instruction.
 |
While a 2.9 MHz instruction rate is better than a 1.6 MHz rate, it’s still quite dismal.
If I cleaned up the CPU so that 2 of the five stages were pipelined–the two stages that didn’t suffer from pipeline conflicts (prefetch and instruction decode), then I could get up to 3.0 MHz. This would be a slight improvement.
On the other hand, if I could fetch two instructions at a time, the second instruction would benefit from the fact that the flash chip is already set up to get a provide the next instruction word. In this case, I could fetch 2 instructions in 36 clocks vice one instruction in 28 clocks. When the CPU performance was factored in, the CPU would now (nominally) take 36 clocks per two instructions, or 18 clocks total (with exceptions) per instruction. This would mean that the CPU could then speed up to a whopping 4.6 MIPS, based upon an (82 MHz/18 CPI).
 |
This *was *going to be the topic of this article–how to read two instructions at a time. It was how I managed to speed up the S6SoC at the time. In a moment, though, I’ll share a better, faster, and cheaper prefetch module just for this blog article.
Before going there, though, I should finish the story of the S6SoC since I made another improvement as well: I compressed instructions.
Using the ZipCPU compressed instruction set, two 16-bit instructions can be stored into a single 32-bit instruction word. The performance isn’t necessarily all that wonderful, but roughly two in ten instructions can be packed together into a single word. (A recent bug-fix suggests the true value might be four in ten instructions, but I haven’t been able to measure this improvement properly yet–so we’ll just use the two in ten number.) I could probably do a bit better if I taught the compiler or the assembler how to re-order instructions to maximize this feature’s usage, but I’ll still take the 10% improvement. Hence, the ZipCPU speed ultimately became somewhere near (82/18/0.8) or 5.7 MHz.
A funny thing happened, though, on the way to putting this blog post together. When I started using yosys to measure the logic usage of this prefetch, I realized two things. First, I was using more logic than I needed to, and second I could adjust the algorithm so that the CPU could run concurrently with this second fetch. In this manner, the prefetch can run continuously. As a result, the (new/modified) performance of this algorithm is now shown below.
 |
At (roughly) 8 clocks per instruction (between branches), this new version should run at roughly 10 MIPS—a big improvement over the 2MIPS we started with. When you factor in the compressed instruction set, this yields an even better 12.8 MIPS when running from flash and an 82MHz clock.
 |
Consider the difference this makes when trying to process an 8k audio stream. Instead of struggling along at 200 CPU instructions per audio sample, I now have closer to 1,600 CPU instructions per audio sample (neglecting branches). For just a little adjustment in logic, then, the CPU now runs MUCH faster.
Before leaving this topic, I would be remiss if I didn’t point out that the ZipCPU can run a lot faster–it just takes more logic to implement the cache necessary to do so. Indeed, we may even be able to come back and discuss how the prefetch plus instruction cache approach is put together in a later article–although we’ll have to see if the Lord is willing.
How dblfetch Works
While I could spend some time discussing how to strip the performance of a QSPI flash controller to its bare minimums, today’s topic is going to be how to keep an instruction fetch operation going so as to achieve the performance shown in Fig 11 above.
 |
As you may recall from our earlier discussion of the simpler prefetch, the ZipCPU prefetch interacts with the CPU using only a small handful of signals:
-
The clock,
i_clk, and reset,i_reset, wires should need no more description. -
On any branch, whether early (unconditional), or late (conditional or indirect), the CPU will raise an
i_new_pcflag and set the new program counter ini_pc. From then until the next branch, the program counter will increment from one instruction to the next. -
There’s also an
i_clear_cacheline, which is used to force the prefetch to mark any cached information as invalid. This allows the CPU to load instructions into a memory area, and then make sure the instructions freshly loaded into memory are the ones the CPU executes later.
These are just the signaling wires coming from the
CPU. Most of the work within the
prefetch,
h, however, is done with the o_valid and o_insn wires returned to the
CPU.
-
o_validindicates that the instruction presented to the CPU is a valid instruction, and by implication that the instruction fetch has completed. -
o_insnis the instruction being presented to the CPU. It has meaning only ifo_validis also true.
Basically, any time o_valid is true, o_insn must contain a valid
instruction. Once set, these values must hold until the
CPU
accepts them by raising the i_stall_n line. (Why this is a negative logic
signal, vs just a *_ready line is a long story …)
-
i_stall_nis an active low line indicating that the CPU is stalled when active (low). For those familiar with the AXI ready signals, this signal is basically a ready signal from the CPU. When this line is high, ando_validis high on the same clock, then the CPU has just accepted an instruction from the prefetch. and it is time to move on to the next instruction.This detail is key, so remember this: when
(o_valid)&&(i_stall_n), the CPU has just accepted an instruction and we can move forward.Hence, any time
(o_valid)&&(!i_stall_n), we’ll need to hold the instruction valid and wait for the CPU to read it.
If this signaling system is new or confusing to you, then I’m going to recommend that you go back and review the formal properties of the wishbone bus, and likewise the formal properties and initial discussion from when we examined the single instruction prefetch.
In this case, we’ll be building essentially the same basic prefetch as before save for a small number of changes.
-
The first change is that we’ll allow up to two requests to be in flight at a time.
-
The second change is that we’ll need to keep track of both responses, and feed them to the CPU one at a time.
-
The first response from the bus will go into the
o_insnregister, and will seto_valid. -
Subsequent responses will also go into the
o_insnregister, if evero_validis false -
If
o_validis true, buti_stall_nis low, indicating that the CPU is stalled, we won’t be able to place the bus return into theo_insnwires to the CPU. Instead, we’ll create a one-instruction cache to place it into.
-
 |
Let’s see if we can draw this out. The process starts with a state machine that will issue two requests. Further requests will be issued if any requests are outstanding when the CPU accepts an instruction from the prefetch.
The rule here, though, is that no request may be made of the bus unless there’s a place to put the result.
 |
On the return end from the
bus,
responses will go either into our o_insn
register to be sent immediately to the
CPU
or into the cache_word if o_insn already has a valid value within it.
Which location the return goes into
will be governed both by the o_valid flag, indicating that o_insn
has a valid instruction within it, by cache_valid, indicating that
the cache_word has a valid instruction within it, and i_stall_n
indicating that everything is moving forward.
The CPU’s Contract with the Prefetch
Since I started working with formal methods, I’ve started thinking of modules within a design as having a contract with the rest of the design. For example, a memory module has a contract to return the values found within the memory at the requested address, and to allow you to change those values and retrieve the changed values later. In the case of a prefetch, the contract is fairly simple: the prefetch module needs to return to the CPU the memory it read from the address the CPU requested. It’s that simple.
To make matters even easier,
yosys
offers two expressions that can help:
$anyseq and $anyconst. These describe “free variables.” They are so
valuable, that I’d like to take a moment longer to discuss these terms.
$anyseq defines an arbitrary value that can change on every clock cycle.
You might find it within a section of Verilog code that looks something like:
wire [N-1:0] some_value;
assign some_value = $anyseq;It’s equivalent to having an unconstrained input (i.e. a “free variable”) to your module, but doesn’t require you to actually create such an input.
$anyconst is similar, only the value of $anyconst will never change within
a run. Indeed, not only is it similar, but you’d write it out in the exact
same way.
wire [N-1:0] some_constant;
assign some_constant = $anyconst;With a just one simple assumption, $anyseq can be turned into an $anyconst,
as in:
wire [N-1:0] some_constant;
assign some_constant = $anyseq;
always @($global_clock)
assume(some_valid == $past(some_value));However, this is only for illustration purposes. $anyconst will work
for us today rather than $anyseq.
Specifically, we can use $anyconst to describe the formal contract between the
CPU and
this prefetch
module. Using $anyconst, we can describe both an arbitrary address in memory,
as well as an arbitrary value (the instruction) that will be at this address.
wire [AW-1:0] f_const_addr;
wire [DW-1:0] f_const_insn;
assign f_const_addr = $anyconst;
assign f_const_insn = $anyconst;Then the basic contract is that any time the
prefetch
tells the
CPU
that it has a valid instruction, i.e. o_valid is true, and that this
instruction comes from the address listed above, f_const_addr, then the
instruction must also match the value listed above as well, f_const_insn.
always @(*)
if ((o_valid)&&(o_pc == f_const_addr))
assert(o_insn == f_const_insn);Well, this is close but it isn’t quite right yet. This doesn’t handle the case where an attempt to read from this instruction address results in a bus error. To handle that case, we’ll need an additional flag to determine if our arbitrary example address references a legal location on the bus.
wire f_const_illegal;
assign f_const_illegal = $anyconst;Using this new flag, the contract then becomes,
always @(*)
if ((o_valid)&&(o_pc == f_const_addr))
begin
assert(o_illegal == f_const_illegal);
if (!o_illegal)
assert(o_insn == f_const_insn);
endWell, even that’s not quite right. I like using the o_illegal bit as a
sticky bit. Once it becomes true, it should stay true until the
CPU and
issues an i_new_pc flag and new i_pc. Alternatively, we can clear it on the
rarer i_reset or i_clear_cache flags. This means that our contract is
instead going to be,
always @(*)
if ((o_valid)&&(o_pc == f_const_addr))
begin
if (f_const_illegal)
assert(o_illegal)
if (!o_illegal)
assert(o_insn == f_const_insn);
endWe’ll also have to add some assumptions to our algorithm in order to meet
this contract. Specifically, we’ll need to assume that any time we read
from the f_const_addr address
that the result returned will be an acknowledgment (not an error) carrying
f_const_insn in i_wb_data if f_const_illegal is false, or a
bus
error
if f_const_illegal is true, but that part will be prefetch specific
so we’ll hold off on that until we get to our actual properties.
Working through the Algorithm
I normally work through an algorithm via pseudocode before presenting it here. Today, we’ll just walk through this by steps–since I’m not sure I have a simple pseudocode to describe it.
So, here’s how this algorithm will function:
- On any reset or request to clear the cache, wait for a new PC to be given
 |
We’ll assume i_new_pc takes place on the clock after i_reset. That means
that on the clock following i_new_pc, we want to initiate a bus request
with the address of the program counter just given within i_pc.
This logic is shown in Fig 13. on the right.
You can see this in Fig 14. on the right.
 |
In that figure, you can see that following a
bus
error:
the bus cycle ends and so o_wb_cyc drops. o_valid and o_illegal are
then both set together. o_valid indicates that the
bus
transaction is complete, o_illegal that it ended with an invalid instruction.
- On any
i_new_pcrequest, start a new bus transaction.
 |
As shown in Fig 15 above, if a
bus
transaction is currently underway when the
CPU
signals an i_new_pc, then the
bus
request is aborted (o_wb_cyc is dropped) and a new one is started on the
clock following. We’ll use the internal register
invalid_bus_cycle, as shown in Fig 15, to mark that a
bus transaction was aborted,
and that a new
bus transaction
needs to be initiated on the next clock.
-
When any bus transaction begins, immediately issue two requests.
This was what we showed above in Fig 3 when we started. Everything starts with two requests. Then, if a response comes back before the second request is issued an additional value will be requested from the bus.
Remember the rule: no request may be issued unless there is a place to put the result–lest the bus respond faster then we are expecting. Hence, the bus transaction starts out with our two instruction “cache” entries empty so we can issue two requests. If one value comes back and leaves our “cache” for the CPU, then we can immediately issue a third request.
-
The initial address requested will be given by the value in
i_pcwheneveri_new_pcis true. Ever after, the request address should increment by one on each clock.This goes for the output PC value,
o_pcas well. It will also be set toi_pcany timei_new_pcis true. However, unlike the bus addresses which increments on every new bus request that is made, this value will instead increment any time the CPU accepts an instruction. -
Responses to the bus will be placed into the
o_insnregister any timeo_validis false, or any time there’s nothing in the cache andi_stall_nis true.We’ll get deeper into these details in the next section.
-
If an instruction is being held in
o_valid, the second return will be placed into acache_word, and then bus transaction will stop and the wishboneCYCline will be lowered.We’ve gone for too long without an image. Here’s what I’m talking about in Fig 16.
It is important that the bus request end if the CPU is stalled for too long (
i_stall_nis low), as the CPU might be stalled at the internal memory vs prefetch arbiter while trying to access the bus. By making sure that we never receive more than two instructions, and then let the bus return to idle, we keep the CPU from entering into a deadlock state.
All of this needs to be subject to the rule that the two element return FIFO cannot be allowed to ever overflow it’s two instruction depth. We’ll use formal properties below to convince ourselves that such will never happen.
The Code
Now that you know the basic idea behind the code, it’s time to examine it in detail. Once we finish, we’ll get into the formal properties necessary to verify that this works in the next section.
We’ll start from the beginning: when shall a bus transaction begin and
end? As you may recall from the formal
properties of the
wishbone bus,
o_wb_cyc will capture anytime we in the middle of one (or more) transactions,
and o_wb_stb will be true anytime we are making a request of the
bus.
You may also remember that o_wb_stb can only ever be true during a
bus
cycle. Hence, o_wb_stb must imply that o_wb_cyc is also true.
The bus initially starts out idle. We’ll also return to an idle on any reset or bus error. This logic is similar to any Wishbone bus master.
initial o_wb_cyc = 1'b0;
initial o_wb_stb = 1'b0;
always @(posedge i_clk)
if ((i_reset)||((o_wb_cyc)&&(i_wb_err)))
begin
o_wb_cyc <= 1'b0;
o_wb_stb <= 1'b0;Next, during any
bus
transaction, we’ll keep issuing transactions
until a last_stb flag becomes true. We’re going to use this last_stb
idea to keep this set of
logic simpler,
since last_stb can be calculated on the prior clock.
end else if (o_wb_cyc)
begin
if ((!o_wb_stb)||(!i_wb_stall))
o_wb_stb <= (!last_stb);Releasing the bus is a little more complicated.
The first step is to count the number of items in flight at any given time.
We’ll place this count into inflight and come back to the logic to do
this later.
We’ll end the transaction on any last acknowledgment. We’re also going to release the bus anytime we’ve made our last request, and nothing is in flight. Finally, anytime a new program counter is given to us, or any time we are asked to clear our cache, we’ll also end this bus transaction.
if (((i_wb_ack)&&(!o_wb_stb)&&(inflight<=1))
||((!o_wb_stb)&&(inflight == 0))
// Or any new transaction request
||((i_new_pc)||(i_clear_cache)))
begin
o_wb_cyc <= 1'b0;
o_wb_stb <= 1'b0;
endThat’s how we’ll end a transaction, but when will one start?
We’re going to need to start a transaction on a couple conditions.
First, if we are idle and the
CPU
asks for a new
PC,
we’ll need to start
a transaction. Likewise, if the last transaction was aborted because the
CPU
requested a new
PC,
then invalid_bus_cycle will be true and we need to start again. Finally,
any time we’ve run our two instruction cache/FIFO
dry, then we’ll start a new
bus
cycle as well.
end else if ((i_new_pc)||(invalid_bus_cycle)
||((o_valid)&&(i_stall_n)&&(!o_illegal)))
begin
// ...
o_wb_cyc <= 1'b1;
o_wb_stb <= 1'b1;
endNormally, when I build a multi-transaction bus master, I know ahead of time how many transaction requests to issue. Examples would be the prefetch plus cache bus master, which always fetches a complete cache line, and the full-featured debugging bus master I like to use. In the case of the debugging bus, the read bus, request tells it how many transactions to request, although the write bus, request just requests an additional transaction.
This bus master is different.
In this case, we want to issue two requests, and then possibly more depending
on whether or not we have enough available spaces. Doing this requires
counting the number of transactions in flight. We’ll do this with the
register, inflight. Upon any successful
bus
request, we’ll increment this value and on
any acknowledgment we’ll decrement it to keep a count of what’s
in flight. (We don’t need to adjust our count on
error,
since the
bus
transaction will always be aborted on any
error
anyway.)
There are some key features of this logic. Because an acknowledgment can come
back when the o_wb_cyc line is low, such as immediately following an
aborted transaction, we’ll just set everything to zero if o_wb_cyc is low.
initial inflight = 2'b00;
always @(posedge i_clk)
if (!o_wb_cyc)
inflight <= 2'b00;
else beginAfter that, we increase the number of items in flight on any accepted bus request, and decrease the number on any acknowledgment. If neither are true, or if both are true, the count won’t change.
case({ ((o_wb_stb)&&(!i_wb_stall)), i_wb_ack })
2'b01: inflight <= inflight - 1'b1;
2'b10: inflight <= inflight + 1'b1;
// If neither ack nor request, then no change. Likewise
// if we have both an ack and a request, there's no change
// in the number of requests in flight.
default: begin end
endcase
endJust as an example of how
easy formal can be,
I knew when I wrote these lines that inflight could never be greater than
two. Hence, I originally placed an assert statement here to that effect.
It has since been moved to our formal section and so we’ll discuss it
below when we get to it. I only bring it up here to discuss an example
situation where it is useful to immediately write a formal property.
Let’s move on to the last_stb piece of logic. You may recall from above
that we used a piece of logic to determine when the current request was the last
bus
request that needed to be issued. Normally when I build a
bus
master, this is a registered value–set on the clock before the last strobe.
A good example of this would be the
DMA controller for the
ZipCPU,
which separates the difficult logic of when to end a
bus
cycle from the already
difficult logic,
describing the
DMA
state machine.
This isn’t that either.
This bus master is different because I want to keep issuing requests anytime the CPU accepts an instruction. In this case, the second strobe will be the last strobe–i.e. if the number in flight is more than one. Likewise if there’s a valid instruction waiting for the CPU then this also needs to be the last bus request.
always @(*)
last_stb = (inflight != 2'b00)||((o_valid)&&(!i_stall_n));The next register, invalid_bus_cycle, is one I’ve tried to get rid of many
times. In many ways it feels redundant. Timing, however, requires it.
Specifically, my problem is this: if i_new_pc comes during the middle of a
bus
cycle, the
prefetch
immediately aborts that
bus
cycle. The
bus
cycle needs to then be re-initiated on the next clock cycle, as shown in Fig 15
above. That’s the purpose of invalid_bus_cycle: to tell the design to start
up a new
bus
cycle after the last one was artificially ended by an i_new_pc request.
initial invalid_bus_cycle = 1'b0;
always @(posedge i_clk)
if (i_reset)
invalid_bus_cycle <= 1'b0;
else if ((o_wb_cyc)&&(i_new_pc))
invalid_bus_cycle <= 1'b1;
else if (!o_wb_cyc)
invalid_bus_cycle <= 1'b0;We discussed above how the
bus
request address, o_wb_addr, will be set by
the address given on any i_new_pc request.
initial o_wb_addr = {(AW){1'b1}};
always @(posedge i_clk)
if (i_new_pc)
o_wb_addr <= i_pc[AW+1:2];Other than on any i_new_pc request, we’ll increment the
bus
address on every successful transaction request but leave it alone otherwise.
else if ((o_wb_stb)&&(!i_wb_stall))
o_wb_addr <= o_wb_addr + 1'b1;We can now look at the o_valid signal. As you may recall, this signal
needs to be true any time a valid instruction is being presented to the
CPU.
We’ll start on reset. On any reset, any i_new_pc request, or any request
to i_clear_cache, we’ll clear this valid signal.
initial o_valid = 1'b0;
always @(posedge i_clk)
if ((i_reset)||(i_new_pc)||(i_clear_cache))
o_valid <= 1'b0;Further, on any valid return from the bus, whether an acknowledgment or an error, we’ll set the valid signal to true.
else if ((o_wb_cyc)&&((i_wb_ack)||(i_wb_err)))
o_valid <= 1'b1;The final piece of logic references what to do if the
bus
isn’t providing an instruction, but the
CPU
has just accepted the one we’ve presented to it within o_insn. In this case,
whether or not we are valid will be determined by whether or not the
second word in our FIFO or cache, cache_word, has a valid value within it.
else if (i_stall_n)
o_valid <= cache_valid;o_valid tells the
CPU
when the instruction from the
prefetch
is a valid instruction. The instruction itself is kept in the o_insn
register, our next item to discuss.
As you’ll recall from above, there are a couple cases to consider with o_insn.
If o_valid isn’t true, then o_insn is a don’t care. If o_valid
is true, but i_stall_n is false, then the
CPU
is busy (stalled), and the
instruction must stay ready and unchanged until the
CPU
is ready to accept it.
Hence, any time o_valid is false, or any time the
CPU
is ready to accept an instruction, then we can update the instruction.
initial o_insn = {(32){1'b1}};
always @(posedge i_clk)
if ((!o_valid)||(i_stall_n))
beginIf the cache word is valid, then we want to present the cache word as the
next instruction word. Otherwise, the next instruction word can only come from
the bus.
While it may not be on the
bus
on this cycle, it will eventually be on the
bus,
i.e. in i_wb_data, and then o_valid will be set on the
next clock–keeping us from changing again until the
CPU
accepts the instruction.
if (cache_valid)
o_insn <= cache_word;
else
o_insn <= i_wb_data;
endAs a side note, you may notice that the logic for this 32-bit word has
been kept very simple. This is
important.
Complex logic on a wide bus can suddenly and greatly increase your logic
usage.
Instead, we are reserving the complex logic for the one or two wire
registers, such as o_wb_cyc or o_wb_stb above, while keeping the logic
for the larger registers, like o_insn, o_wb_addr, or even o_pc simple.
Speaking of o_pc, that’s our next register to examine. The
o_pc register is very similar to the o_wb_addr register that we dealt with
above. It needs to be set on any i_new_pc event, and otherwise incremented
any time the output instruction is valid, o_valid, and the
CPU
accepts that instruction, i_stall_n.
initial o_pc = 0;
always @(posedge i_clk)
if (i_new_pc)
o_pc <= i_pc;
else if ((o_valid)&&(i_stall_n))
o_pc[AW+1:2] <= o_pc[AW+1:2] + 1'b1;You’ll notice that we kept this logic
simple as well,
since the number of LUTs required by
this logic will be required for every bit of o_pc.
Just to illustrate this point, the o_pc logic alone uses 61 4-LUTs of the
total 246 LUTs used by the design as a whole on an iCE40. That’s a whole 24%
of the total logic for this design–and it’s a very minimal piece of logic at
that.
The final word used to interface with the rest of the
CPU
is the o_illegal register. This is the flag used to tell the
CPU
that the attempt to read from this address resulted in a
bus
error.
We’ll clear this flag on any reset, or i_new_pc request. Likewise, we’ll
clear it on any request to clear the cache, i_clear_cache.
initial o_illegal = 1'b0;
always @(posedge i_clk)
if ((i_reset)||(i_new_pc)||(i_clear_cache))
o_illegal <= 1'b0;As with o_insn, nothing is allowed to change if we have a valid
instruction that the
CPU
hasn’t yet accepted the last instruction, or equivalently if
(o_valid)&&(!i_stall_n).
else if ((!o_valid)||(i_stall_n))
beginThat brings us to how o_illegal needs to be set. If the cache_word is
valid, then it moves into the o_insn position. At that same time,
if the cache_illegal flag associated with that cache_word is true,
that will indicate that a
bus
error
was returned while attempting to request the second word. This illegal
flag will then also need to move into the o_insn position and we’ll set
o_illegal in that case.
Otherwise, if the cached value isn’t valid, then there’s nothing in our
cache and we’ll need to set the o_illegal flag immediately on a
bus
error,
since that’s the value directly going into the first output position,
o_insn.
if (cache_valid)
o_illegal <= (o_illegal)||(cache_illegal);
else if ((o_wb_cyc)&&(i_wb_err))
o_illegal <= 1'b1;
endOk, so we’ve now dealt with the output values to the
CPU:
o_valid, o_insn, and o_illegal. These are the values associated
with the current item being sent to the
CPU
from our two instruction FIFO.
Let’s now turn our attention to that second response from the bus, the other
element in our two instruction FIFO. We’ll store this value in the word
cache_word, and mark it as valid using cache_valid.
Should this word be the result of a
bus
error,
we’ll then set the value cache_illegal to reflect this.
We’ll start here, though, with cache_valid. On any reset, any new
PC,
or any time we clear the cache, cache_valid needs to be cleared.
initial cache_valid = 1'b0;
always @(posedge i_clk)
if ((i_reset)||(i_new_pc)||(i_clear_cache))
cache_valid <= 1'b0;Otherwise, we need to set it any time o_valid is true, the
CPU is
stalled (!i_stall_n), and a return comes in from the
bus.
In a similar fashion, we’ll need to clear this flag anytime the cache_word
gets moved into the o_insn position and presented to the
CPU.
This will be when i_stall_n is true, but not response is coming from the
bus.
The only catch is when/if cache_valid is already true and a new response
comes back from the
bus. (This should never
happen.) In this case, cache_valid needs to be set as well.
else begin
if ((o_valid)&&(o_wb_cyc)&&((i_wb_ack)||(i_wb_err)))
cache_valid <= (!i_stall_n)||(cache_valid);
else if (i_stall_n)
cache_valid <= 1'b0;
endThis brings us to the cache word. As you’ll recall from above, the
cache_word register is the second word in the output FIFO after o_insn.
This value is completely irrelevant, though, unless cache_valid (above)
is also true. Hence, we can set it to whatever returns from the
bus in
i_wb_data whenever it returns. We’ll use other logic, above in cache_valid,
to determine whether or not this value is relevant to us.
always @(posedge i_clk)
if ((o_wb_cyc)&&(i_wb_ack))
cache_word <= i_wb_data;Obviously this will fail if an acknowledgment is returned while cache_valid
is true. We’ll need to make certain this never happens, and we’ll use the
formal methods
below to convince ourselves that this will never happen.
The last value is the cache_illegal value. This flag is used to
indicate that the second response from the
bus was a
bus
error,
i_wb_err. As before, this value is cleared on any i_reset, i_new_pc,
or i_clear_cache. After that, it’s set on any i_wb_err return where
the first
bus
return position in the FIFO is stuck waiting on the
CPU,
(o_valid)&&(!i_stall_n).
initial cache_illegal = 1'b0;
always @(posedge i_clk)
if ((i_reset)||(i_clear_cache)||(i_new_pc))
cache_illegal <= 1'b0;
else if ((o_wb_cyc)&&(i_wb_err)&&(o_valid)&&(!i_stall_n))
cache_illegal <= 1'b1;Remember that the i_wb_err flag needs to be cross-checked with the
o_wb_cyc flag, since suddenly dropping o_wb_cyc might still allow
i_wb_err to return on the next cycle when o_wb_cyc is low.
That’s it! At this point, we have a completed prefetch module that will continue fetching instructions from memory until it’s two instruction word FIFO is full and the CPU remains stalled.
But … does it work? That’s the point of the formal properties presented in the next section.
The Formal Properties
A prefetch has two basic interfaces it needs to maintain, as shown above in Fig 12. The first is formally characterized by the set of wishbone properties. The second interface is to the CPU. Therefore, we’ll spend some time putting together the assumptions and assertions necessary for interacting with the CPU. Finally, we’ll present the logic necessary to formally verify that this prefetch formally maintains its contract with the CPU as we discussed above.
We’ll start with the
formal properties
necessary for interacting with the
wishbone bus.
Aside from assuming that i_reset is true on startup,
initial `ASSUME(i_reset);most of this is already done for us by the fwb_master module.
localparam F_LGDEPTH=2;
wire [(F_LGDEPTH-1):0] f_nreqs, f_nacks, f_outstanding;
//
// Add a bunch of wishbone-based asserts
fwb_master #(.AW(AW), .DW(DW), .F_LGDEPTH(F_LGDEPTH),
.F_MAX_STALL(2),
.F_MAX_REQUESTS(0), .F_OPT_SOURCE(1),
.F_OPT_CLK2FFLOGIC(F_OPT_CLK2FFLOGIC),
.F_OPT_RMW_BUS_OPTION(1),
.F_OPT_DISCONTINUOUS(0))
f_wbm(i_clk, i_reset,
o_wb_cyc, o_wb_stb, o_wb_we, o_wb_addr, o_wb_data, 4'h0,
i_wb_ack, i_wb_stall, i_wb_data, i_wb_err,
f_nreqs, f_nacks, f_outstanding);You may remember how we built that property list together earlier, right?
In this case, the important parts of this are the parameters being used
to set this up. First, we’re only expecting a two items to ever be in
flight at a time, so we can set F_LGDEPTH to two. Second, just to keep
things moving, we’ll assume that the
bus
will never stall more than 2
clocks at a time, F_MAX_STALL(2). We won’t set a maximum number of
requests, since our particular goal is to allow us to continually make
requests until our result buffer is full. F_OPT_SOURCE is set to
true, just to check that o_wb_stb gets set to true any time
o_wb_cyc rises.
It’s really just about that simple, but there is one exception: we’ll
need to tie our logic
to the f_nreqs, f_nacks, and f_outstanding signals, or we won’t pass the
formal induction
step.
That logic is coming up in a bit.
The next section discusses the assumptions associated with interacting with
the CPU.
To make sure these statements hold properly, we’ll use a variety
of f_past_* variables. We’ll use these in place of the $past() operator,
since
Verilator
doesn’t support it (yet). This includes f_past_reset,
f_past_clear_cache, f_past_o_valid, and f_past_stall_n.
The first assumption is that following any reset, the CPU will provide a new instruction address on the next clock cycle.
always @(posedge i_clk)
if ((f_past_valid)&&(f_past_reset))
assume(i_new_pc);We’ll assume the same of an i_clear_cache request, that the next clock
cycle will provide us with an new
PC
value.
always @(posedge i_clk)
if ((f_past_valid)&&(f_past_clear_cache))
assume(i_new_pc);Further, we know from the
CPU’s code
that the i_clear_cache request will never be held high for two clocks
in a row.
always @(posedge i_clk)
if (f_past_clear_cache)
assume(!i_clear_cache);This brings us to a rather unusual assertion.
Some time ago, I got frustrated trying to translate between word addresses
on the
bus
and the byte addresses the
CPU
uses. In a fit of frustration, I converted all of the versions of the
program counter
maintained within the
design to byte addressing. That means that the bottom two bits of
i_pc need to be zero. It also means the bottom two bits of o_pc will
need to be zero, but we’ll get to that one later.
always @(*)
assume(i_pc[1:0] == 2'b00);The result of using byte addressing is that I can now correlate these program counter values with the byte addresses in a dump of any ZipCPU executable.
Now let’s talk about the i_stall_n line. Following any reset, the
CPU
will be reset and there will be no reason to stall. Hence, following any
reset i_stall_n will be true indicating that the
CPU
is ready to accept an instruction.
initial assume(i_stall_n);
always @(posedge i_clk)
if ((f_past_valid)&&(f_past_reset))
assume(i_stall_n);In a similar manner, the CPU will never become busy and stall unless it has already accepted an instruction.
always @(posedge i_clk)
if ((f_past_valid)&&(!f_past_o_valid)&&(f_past_stall_n))
assume(i_stall_n);Our last criteria regarding our interaction with the CPU is the assumption that the CPU will always accept an instruction within four clocks.
localparam F_CPU_DELAY = 4;
reg [4:0] f_cpu_delay;
// Now, let's look at the delay the CPU takes to accept an instruction.
always @(posedge i_clk)
// If no instruction is ready, then keep our counter at zero
if ((!o_valid)||(i_stall_n))
f_cpu_delay <= 0;
else
// Otherwise, count the clocks the CPU takes to respond
f_cpu_delay <= f_cpu_delay + 1'b1;
always @(posedge i_clk)
assume(f_cpu_delay < F_CPU_DELAY);This isn’t necessarily true. A divide instruction might cause the CPU to stall for 30+ clocks. However, it’s good enough to speed our way through formal verification.
We can now turn to some assertions about our outputs to the CPU. This isn’t (yet) the contract we discussed above, but we’ll get to that in the next section.
We’ll start with the assertion about the output
wishbone bus
address.
Anytime a new request is accepted by the
bus,
the o_wb_pc should increment. The only exception is following an
i_new_pc signal–when it should be set by the new i_pc value.
always @(posedge i_clk)
if ((f_past_valid)&&($past(o_wb_stb))&&(!$past(i_wb_stall))
&&(!$past(i_new_pc)))
assert(o_wb_addr <= $past(o_wb_addr)+1'b1);When it comes to the output values, the rule is that anytime the output
is valid and the
CPU
is stalled, i.e. any time (o_valid)&&(!i_stall_n),
then the output values need to stay constant.
always @(posedge i_clk)
if ((f_past_valid)&&(!$past(i_reset))
&&(!$past(i_new_pc))&&(!$past(i_clear_cache))
&&($past(o_valid))&&(!$past(i_stall_n)))
begin
assert($stable(o_pc));
assert($stable(o_insn));
assert($stable(o_valid));
assert($stable(o_illegal));
endThe same is true for that second cached word as well. If that cache position is valid, yet the CPU is stalled, then it should never change.
always @(posedge i_clk)
if ((f_past_valid)&&(!$past(i_reset))
&&(!$past(i_new_pc))&&(!$past(i_clear_cache))
&&($past(o_valid))&&(!$past(i_stall_n))
&&($past(cache_valid)))
begin
assert($stable(cache_valid));
assert($stable(cache_word));
assert($stable(cache_illegal));
endIn a fashion similar to o_wb_addr above, o_pc should only ever increment,
and it should only do that if an instruction has been accepted–with the
exception of any time i_new_pc is asserted.
always @(posedge i_clk)
if ((f_past_valid)&&(!$past(i_new_pc))
&&($past(o_valid))&&($past(i_stall_n)))
assert(o_pc[AW+1:2] == $past(o_pc[AW+1:2])+1'b1);As with i_pc[1:0] and the frustration I described above, the bottom two
bits of the o_pc address are unused. Let’s assert here that they remain zero.
always @(*)
assert(o_pc[1:0] == 2'b00);Upon any
bus
error
return, one of either o_illegal or cache_illegal should be
set. Further, if o_illegal is set, so too should be o_valid to indicate
this is a valid return, and the same for cache_valid.
always @(posedge i_clk)
if ((f_past_valid)&&(!$past(i_reset))
&&(!$past(i_new_pc))
&&(!$past(i_clear_cache))
&&($past(o_wb_cyc))&&($past(i_wb_err)))
assert( ((o_valid)&&(o_illegal))
||((cache_valid)&&(cache_illegal)) );Any time o_illegal gets set, o_valid should also be set at the same time.
o_illegal will then stay true until cleared by a i_reset, i_new_pc, etc,
so this is the most important part of the check.
always @(posedge i_clk)
if ((f_past_valid)&&(!$past(o_illegal))&&(o_illegal))
assert(o_valid);We’ll need to check for the same thing in the cache as well. Hence, any time the cached value was not illegal before, and the cache remains invalid now, then the cache cannot have become illegal during this clock as well.
always @(posedge i_clk)
if ((f_past_valid)&&(!$past(cache_illegal))&&(!cache_valid))
assert(!cache_illegal);Following any i_new_pc request, o_valid must be low. This assertion
comes from searching for a bug in the instruction
decoder.
always @(posedge i_clk)
if ((f_past_valid)&&($past(i_new_pc)))
assert(!o_valid);Finally, any time we transition from o_valid to !o_valid, we should also
be starting a
bus
cycle–lest we somehow get stuck.
always @(posedge i_clk)
if ((f_past_valid)&&(!$past(i_reset))&&(!$past(i_clear_cache))
&&($past(o_valid))&&(!o_valid)&&(!o_illegal))
assert((o_wb_cyc)||(invalid_bus_cycle));Okay, that was a lot of properties! Are you still with me?
At this point, we are finally ready for the contract with the CPU! Remember how we discussed this above? Let’s now take a look at how it’s done.
We’ll start with three arbitrary values, an address, f_const_addr, an
instruction, f_const_insn, and whether or not that address will return a
bus
error,
f_const_illegal.
wire [AW-1:0] f_const_addr;
wire [DW-1:0] f_const_insn;
wire f_const_illegal;
// ...
assign f_const_addr = $anyconst;
assign f_const_insn = $anyconst;
assign f_const_illegal = $anyconst;The next section is a bit verbose. It probably doesn’t need to be. But, just to tell the story …
Over the course of time, while working with these values, I got somewhat
frustrated with the waveform viewing tool I was using. One frustration was
my formal properties often contained something like if ((A)&&(B)&&...) and
I could never tell when
something failed which of A, B, or (other) wasn’t true. To keep this
from happening, I assigned wires (below) to the various comparisons checks
I needed to do. This way, I can examine these wires on any trace
failure and see why things failed.
wire f_this_addr, f_this_pc, f_this_req, f_this_data,
f_this_insn;
assign f_this_addr = (o_wb_addr == f_const_addr);
assign f_this_pc = (o_pc == { f_const_addr, 2'b00 });
assign f_this_req = (i_pc == { f_const_addr, 2'b00 });
assign f_this_data = (i_wb_data == f_const_insn);
assign f_this_insn = (o_insn == f_const_insn);That said, I’m undecided as to whether or not this frustration should lead me to split out wires like this in the future.
Ok, that’s the setup, here’s the contract: on any clock where the result
is valid, and where it’s our f_const_addr address being returned, then
we need to be returning either this instruction, f_const_insn, or
o_illegal if this instruction returned a
bus
error.
always @(*)
if ((o_valid)&&(f_this_pc))
begin
if (f_const_illegal)
assert(o_illegal);
if (!o_illegal)
assert(f_this_insn);
endOf course, this will only work if the bus itself returns either this instruction or an error upon request. Since this is an input of the prefetch, it needs to be assumed.
The trick in making this assumption is that we need to know which return
of the many
bus
requests that we’ve made is the return value for this contract instruction.
Given that we increment o_wb_addr any time we send a
bus
request in flight, and given that
f_outstanding counts the number of items in flight, we can then know if this
return is our address by subtracting from o_wb_addr the number of items
in flight.
assign f_this_return = (o_wb_addr - f_outstanding == f_const_addr);Using this predicate, we can now say that if the next
bus
return will be for this request (i.e. f_this_return is set), then if
we receive an acknowledgment from the
bus
the data should be f_const_insn.
always @(*)
if ((o_wb_cyc)&&(f_this_return))
begin
if (i_wb_ack)
assume(i_wb_data == f_const_insn);To handle whether we get a
bus
error
or an acknowledgment, we’ll do it this way: If f_const_illegal is true, we
should only get an i_wb_err from the
bus
and never any valid acknowledgment. Likewise the reverse: if f_const_illegal
is false, we should only ever get an acknowledgment from the
bus.
This particular way of describing this behavior allows the
bus.
to still take its own sweet time to return any values, but
yet still forces the
bus
error
when appropriate–i.e., when f_const_illegal is set.
if (f_const_illegal)
assume(!i_wb_ack);
else
assume(!i_wb_err);
endThere’s a corollary to our contract above. This corollary has to do
with the cached value that hasn’t yet been given to the
CPU.
In this case, we still need to assert that this cached value holds to our
contract. While this wouldn’t be necessary for a simple Bounded Model Check
(BMC), it is a necessary
requirement
in order to pass the formal
formal
induction step.
Hence, if the address within the cache, the next o_pc address, o_pc+4,
matches our arbitrary address, f_const_addr, and if the cache has a valid
value within it, then these conditions apply: unless the cache value is
illegal, it should contain our arbitrary instruction word. Likewise,
if the cache value is supposed to be illegal, then cache_illegal
should be true as well.
always @(*)
if ((o_pc[AW+1:2] + 1'b1 == f_const_addr)&&(cache_valid))
begin
if (!cache_illegal)
assert(cache_word == f_const_insn);
if (f_const_illegal)
assert(cache_illegal);
endThat’s our contract. If we meet that contract, then we’ll know this design works.
always @(posedge i_clk)
if ((f_past_valid)&&(!$past(cache_illegal))&&(!cache_valid))
assert(!cache_illegal);We’re not done yet, however.
First, we want to make certain that our two instruction FIFO will never overflow. As we’ve written our design above, any overflow would be catastrophic. Hence, any time we request a new value, we must have a place to put it. In other words, either the cache value must be empty, or the CPU must have just accepted a value.
always @(*)
if (o_wb_stb)
assert((!cache_valid)||(i_stall_n));In a similar vein, any time both the output and the cache value are both valid, then we need to guarantee that we aren’t requesting any more values, and that nothing is in flight.
always @(*)
if ((o_valid)&&(cache_valid))
assert((f_outstanding == 0)&&(!o_wb_stb));These should be sufficient to keep us from overflowing this two instruction FIFO.
However, the formal properties we’ve listed so far aren’t sufficient to guarantee that the design will pass the induction step. In order to pass induction, we need to restrict the induction engine so that it only considers reachable states.
To make certain we don’t over-restrict our design, we’ll limit ourselves here to only using assert statements. As a result, the BMC and induction stages will be able to catch anything that is over constrained–as long as the number of stages examined in BMC is more than the stages examined during induction.
The first assertion is that any time we have at least one item in our FIFO,
that is any time o_valid is true, and any time that item isn’t moving forward,
then there can only be one or zero
bus
requests outstanding.
always @(*)
if ((o_valid)&&(!i_stall_n))
assert(f_outstanding < 2);The next assertion follows, but in this case any time the FIFO is completely empty we allow ourselves to have up to two requests in flight.
always @(*)
if ((!o_valid)||(i_stall_n))
assert(f_outstanding <= 2);Further, any time we are within a
bus
cycle, i.e. o_wb_cyc is high, but yet we’ve stopped making
bus
requests, i.e. o_wb_stb is low, then there should
be some number of requests in flight.
always @(posedge i_clk)
if ((f_past_valid)&&($past(o_wb_cyc))&&(!$past(o_wb_stb))
&&(o_wb_cyc))
assert(inflight != 0);Just to make sure we captured everything, let’s state this again: on any return from the bus, there must be a place to put that return.
always @(*)
if ((o_wb_cyc)&&(i_wb_ack))
assert(!cache_valid);Further, our design has two separate counters of how many items are within
flight. One is from the f_outstanding counter created within the
formal WB properties,
module, and the other our inflight counter.
These two counters need to be identical any time the bus, is in use.
always @(posedge i_clk)
if (o_wb_cyc)
assert(inflight == f_outstanding);Now let’s look at the address of the request being made, vs the address being given to the CPU.
First, upon any return from the
bus,
that goes into o_valid, the address
of the value returned needs to be equal to the value given to the
CPU.
assign this_return_address = o_wb_addr - f_outstanding;
assign next_pc_address = o_pc[AW+1:2] + 1'b1;
always @(posedge i_clk)
if ((f_past_valid)&&($past(o_wb_cyc))
&&(!$past(i_reset))
&&(!$past(i_new_pc))
&&(!$past(i_clear_cache))
&&(!$past(invalid_bus_cycle))
&&(($past(i_wb_ack))||($past(i_wb_err)))
&&((!$past(o_valid))||($past(i_stall_n)))
&&(!$past(cache_valid)))
assert(o_pc[AW+1:2] == $past(this_return_address));This isn’t enough, though, to constrain the induction engine. I know, I tried.
Getting this design to pass the induction step required running the induction engine many times, then looking at the failures and trying to find out which wires or values didn’t make sense. When you find them, you look at them and wonder, how on earth did that happen? That doesn’t follow my design principles! Yes, but you need to tell the induction step engine that.
So, let’s look at the case where o_valid isn’t true, but yet we are within a
bus
cycle. In this case, o_pc must be the address of the next request
that will be returned from the
bus.
always @(posedge i_clk)
if ((f_past_valid)&&($past(o_wb_cyc))&&(!o_valid)&&(!$past(i_new_pc))
&&(o_wb_cyc))
assert(o_pc[AW+1:2] == this_return_address);We need to check the same thing with the cache word. Any time the cache
becomes valid, the address coming back needs to be one past the o_pc
address being presented to the
CPU.
always @(posedge i_clk)
if ((f_past_valid)&&($past(o_wb_cyc))
&&(!$past(cache_valid))&&(cache_valid))
assert(next_pc_address == $past(this_return_address));The final step looks at these relationships a bit more thoroughly. We’ll examine only those times, though, when the bus is active.
always @(posedge i_clk)
if ((f_past_valid)&&($past(o_wb_cyc))&&(o_wb_cyc))
beginIf there’s one active value in our FIFO, then anything returned from the bus should have an address given by our next bus address.
if ((o_valid)&&(!cache_valid))
assert(this_return_address == next_pc_address);Likewise anytime we have no valid instructions, the next value to be returned
by the
bus
must match the next
PC
value, o_pc, to be sent to the
CPU.
else if (!o_valid)
assert(this_return_address == o_pc[AW+1:2]);Finally, any time the bus is idle, and there’s only one word in our cache and it’s not illegal, then the address remaining on the bus needs to be the next address to be requested.
end else if ((f_past_valid)&&(!invalid_bus_cycle)
&&(!o_wb_cyc)&&(o_valid)&&(!o_illegal)
&&(!cache_valid))
assert(o_wb_addr == next_pc_address);This leaves us with only two more assertions. These are sort of dogs and cats assertions that don’t fit under any other category above.
First, the invalid_bus_cycle should only ever be true if we aren’t in a
bus
cycle. This assertion was added to make certain I could simplify
some of the assertions above. Since I know it is true, I could make the
other assertions simpler.
always @(*)
if (invalid_bus_cycle)
assert(!o_wb_cyc);Finally, the cache_valid signal should never be true unless o_valid is
also true. This lines up with the idea that cache_valid is our signal that
the second item within our two-element FIFO is valid, so therefore the first
item in the FIFO must also be valid in these cases as well.
always @(*)
if (cache_valid)
assert(o_valid);Wow! That was a lot of work on those properties! The cool thing about these, though, is that now that I have these properties, I can then test simple logic changes to my design, such as trying to remove LUTs to make the design simpler, and see if those changes affect the functionality of this design.
Cover Properties
I haven’t presented cover properties before, although they are a valuable
part of
formal methods.
The cover property is very different from the assume an assert properties
above. Indeed, cover is called a “liveness” property, unlike
assume and assert which are called “safety” properties. The difference is
that assume and assert properties must apply to all traces, whereas a
cover property only needs to apply to a single trace to be true.
A quick Google search suggests that there’s a bit of a disagreement as to whether “liveness” properties are even needed, or whether “safety” properties are sufficient.
While I’m not going to enter into that debate today, I will note that
cover statements can be used while you are building your design to
see if it is working.
As an example, before I listed out all of the properties in the last
section, I wanted to know if this routine might ever get a third
acknowledgment from the same
bus
cycle. If you’ll remember from Fig 11 above, this was part of the purpose
of
this design
in the first place–to be able to continue the
bus
cycle as long as possible. Therefore, I put the following cover
statement into my design.
always @(posedge i_clk)
cover((f_past_valid)&&($past(f_nacks)==3)
&&($past(i_wb_ack))&&($past(o_wb_cyc)));When this cover statement failed at first, I knew I didn’t have my design
right yet. Further, when I dug into the problem, I discovered that this
cover statement was failing not due to my logic, but rather due to some
erroneous assumptions I had made.
Erroneous assumptions can be particularly problematic in
formal methods,
especially if you are only using the “safety” properties, assume and assert,
since an erroneous assumption will artificially limit your proof. Worse yet,
you might not notice that your assumptions are creating this artificial
limit. Such an assumption might then give you a false assurance that your
design works–even though it does not. (Yes, I’ve been burned by
this
more than once.)
Logic Usage
If you’ll remember from when we started, the purpose of this particular prefetch module was to be a compromise–it was to have better performance than our one instruction prefetch, but not nearly as much as we might have with a proper instruction cache. It’s also supposed to be a (fairly) low logic design.
So, for a small design, how did we do?
In particular, I’d like to place this prefetch into both a TinyFPGA and the MAX1000 from Arrow. Will it fit?
The iCE40 FPGA within the TinyFPGA board is perhaps the most constrained of these two. This FPGA has just less than 8k 4-LUTs available to it. With just a simple yosys script,
read_verilog dblfetch.v
synth_ice40we can easily measure this components usage on an iCE40–in only a half-second no less (try doing that with a vendor tool!). You can see the LUT4 usage of these various components in the table below.
| Prefetch | LUT4s | iCE40 Device usage |
|---|---|---|
| Single | 74 | 1.0% |
| Double | 247 | 3.2% |
| (Before) | 277 | 3.6% |
| w/ 4k Cache | 621 | 8.0% |
As you can see from the table, this module offers an area compromise between the slowest prefetch module and the full prefetch and cache module.
Running the ZipCPU with this prefetch
If you want to try running the ZipCPU
or even
ZBasic with this
this prefetch
installed, all you need to do is to adjust the flags in
cpudefs.v.
Specifically, you’ll want to make certain the OPT_SINGLE_FETCH define is
commented,
// `define OPT_SINGLE_FETCHand the OPT_DOUBLE_FETCH line is not,
`ifndef OPT_SINGLE_FETCH
`define OPT_DOUBLE_FETCH
`endifYou may recall discussing this comparison in a previous
article,
only now this compromise prefetch
module
has been updated for better performance and lower logic. Hence, if you’ve
downloaded the ZipCPU before, you’ll
want to do a git pull to get the latest version of
this module.
Conclusion
While it’s generally true that nothing comes for free, today’s post presents a bit of an exception. By redesigning my original dblfetch module, used by the S6SoC and some other ZipCPU low logic implementations, we were able to get both better performance and fewer LUTs. Hence, there are two conclusions we might draw:
-
In general, the more LUTs you apply to a soft-core CPU, the faster the CPU will be.
-
There exist times when a better design can achieve more or better performance. Today’s post represents one of those times. Such performance increases, though, do tend to be asymptotic over time.
What made the difference? This new/updated prefetch doesn’t use a two element memory array, nor the associated pair of valid signals, to capture the two elements returned by the bus.
How about the formal methods we used? Did they help? To this I’ll answer both yes and no. The first time I used this logic in a simulated board, the CPU test failed. That’s the “No” part of the answer. However, the logic failed within the early branch logic in the instruction decoder, not the prefetch. Indeed, this updated prefetch has yet to have any failures since passing formal verification.
Sadly, this wonderful anecdote of the performance of formal methods isn’t nearly as clear as I might like it to be. The logic that failed within the instruction decoder had already been formally verified. Apparently, that proof just wasn’t sufficient and I must still be only learning formal methods.
The one question we haven’t answered is just how much faster is this prefetch? That is, how does it’s performance quantitatively compare to the other ZipCPU prefetch modules? I’m going to hold those questions off, though, for a future article on how to measure your CPU’s performance via a benchmark test–such as the Dhrystone benchmark. Such a benchmark test will also bring us face to face with the fact that our CPU speed measurements above weren’t accurate at all since they ignored the (very significant) cost of branching.
Many will say to me in that day, Lord, Lord, have we not prophesied in thy name? and in thy name have cast out devils? and in thy name done many wonderful works? And then will I profess unto them, I never knew you: depart from me, ye that work iniquity. (Matt 7:22-23)