
Makefiles for formal proofs with SymbiYosys
It seems that the more I work with the ZipCPU, the more options it accumulates.
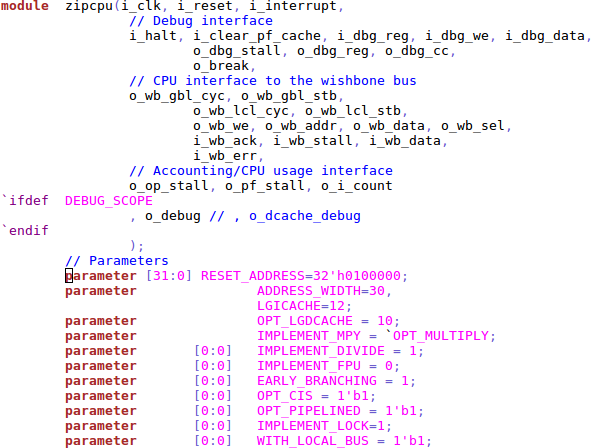 |
I simplified the CPU options somewhat to present Fig. 1, but you can see all the CPU options and their settings in the ZipCPU GitHub repository.
First it was the prefetch: I built a basic prefetch, then one that can issue two bus requests at once, then one with a fullly integrated I-cache. In each case, I wanted more performance but didn’t want to give up the ability of building the ZipCPU in an extremely low logic configuration.
Then it was the multiplies: not every board I worked with had the embedded DSP elements required for hardware accelerated multiplies. Indeed, some that had embedded DSP elements couldn’t handle a 32x32 bit multiply within a single clock (Spartan 6). This forced me into two separate multiplication implementations. Then, the fact that the iCE40 has no DSPs lead to an additional multiplication implementation just to handle that environment.
 > > |
The initial memory subsystem, while working, was cripplingly slow. A faster memory subsystem was written to replace it, and then a proper data cache was written to replace that. On top of that, the ZipCPU can optionally support a lock instruction for atomic access, a compressed instruction set, a set of CPU-local peripherals, and more.
If those weren’t enough changes, the instruction decoder needs to support all of the various instruction set extensions. Lock instructions need to be honored by the memory module, unless no lock instruction is implemented. Multiplication instructions need to be honored if enabled, while creating illegal instruction exceptions if not. Some of the options need special decoding, such as the simulation instructions or the early branching instructions.
This leaves me with an ongoing and growing problem: how do you formally verify a core that has so many options associated with it?
Let’s look at this problem from both the standpoint of the SymbiYosys script file, as well as a supporting Makefile.
SymbiYosys Tasks
While the ZipCPU is highly configurable, it doesn’t make sense to test every permutation of the various configurations. Therefore, let’s look over some of the more common configuration settings used by the ZipCPU. More than that, we’ll give each of these configurations names. These names will us remember the configuration set, as well as helping to make our SymbiYosys configuration simpler in a moment.
-
dcache
This new option describes a configuration that uses the brand new (formally verified, Xilinx Series-7 proven) data cache. If you want performance from the ZipCPU, this is no-holds barred attempt at high speed and full features.
This is the configuration I am testing within my OpenArty project, in case you want to see it in action. (You may need to check out the dev branch where it exists today.)
-
piped
Prior to the data cache, this configuration was the no-holds barred high speed, full featured ZipCPU version. It describes a fully pipelined implementation containing an instruction cache, multiplies, divides, compressed instruction set, and early branching capability. (The early branching capability allows you to branch from the decode stage, without waiting for the later stages. It applies only to unconditional branches.)
-
nopipe
This is the same thing, only we shut down everything we don’t need: no pipeline CPU (forcing a minimum of 3 clocks per instruction), no multiplies, no divide instructions, but still supports the compressed instruction set.
-
lowlogic
Much to my surprise, the no-pipelined option wasn’t as small as I needed to get for some implementations, so this version drops the compressed instruction set support.
-
ice40
Didn’t we get rid of enough stuff yet?
Apparently not.
The iCE40 doesn’t support distributed RAM. All reads from the register file need to go directly into a register first, and only on the next clock can we do anything with them.
Using SymbiYosys, we can declare different “tasks” to verify each of these configurations. The following code declares five such “tasks”, one on each line.
[tasks]
dcache full_proof dcache
piped full_proof no_dcache
nopipe nopipe no_dcache
lowlogic nopipe no_dcache
ice40 nopipe no_dcache nobkramNotice the format of this section. It starts with a [tasks] line. Every
line thereafter begins with the name of a task. In our case, these represent
the various configurations we just outlined above. The second half of the line
is more interesting. This consists of a series of labels which will also be
accepted as task names later. That way, we can specify ice40 and get
all of the nopipe (non-pipelined) options, together with the no_dcache
option and the more critical nobkram option.
 |
How might we use this? There are two basic approaches. First, we can begin
any line following in our
SymbiYosys
script with a task name followed by a colon. Once done, everything
following is only executed if that given task name is the active
task. This applies to the aliased names as well, such as full_proof or
no_dcache.
[options]
mode prove
depth 18
dcache: depth 9
piped: depth 14
nopipe: depth 11
lowlogic: depth 10
ice40: depth 11So far, this is kind of interesting but not all that useful.
Let’s consider some other things yosys offers.
Using yosys, you can set a macro. You might recognize macros by their Verilog usage:
// Define a macro, NO_DISTRIBUTED_RAM
`define NO_DISTRIBUTED_RAM
//
`ifdef NO_DISTRIBUTED_RAM
// Code that only gets executed if `NO_DISTRIBUTED_RAM` is defined
`else
// Code that only gets executed if `NO_DISTRIBUTED_RAM` is not defined
`endifOne problem with this sort of declaration is that it isn’t clear whether the macro defined in one file will remain active in another.
Alternatively, we could use a yosys command to set this macro but only for some configurations.
[script]
nobkram: read -define -DNO_DISTRIBUTED_RAM
read -define -DZIPCPU
#
# ... files the ZipCPU depends upon have been skipped here
# for brevity
#
read -formal zipcpu.vThis defines the macro NO_DISTRIBUTED_RAM across all input files, but only
if nobkram is the active task. Likewise, ZIPCPU is defined for all
tasks. This latter definition is how I handle telling submodules if they
are being verified as separate modules or as submodules
instead.
Another very useful yosys
command is the chparam
command. You can use this to change
the value of any parameter within your logic. As examples, the
ZipCPU has several high
level parameters. Perhaps you may have noticed some of them in Fig 1. above.
For example, IMPLEMENT_FPU is a single bit parameter
that controls whether the (still not yet existent) floating point unit (FPU)
is included. As a more relevant example, OPT_LGDCACHE controls the size
of the
data cache,
and whether the
data cache,
is included at all. If this value is set to zero, no
data cache
will be included in the build, whereas if it is non-zero it sets the size
of the cache.
 |
For this, we’ll use the second approach for specifying task-configurations, as shown in Fig. 4 on the right. In this case, we can start a set of task-specific commands using the task name and a colon on a line by itself.
chparam -set IMPLEMENT_FPU 0 zipcpu
dcache:
chparam -set OPT_LGDCACHE 10 zipcpu
no_dcache:
chparam -set OPT_LGDCACHE 0 zipcpuThis process is continued until either another task name, or
until a line containing two -s by themselves. Hence, the definition of the
full_proof ZipCPU configuration shown
below, as well as the minimal nopipe-lined option and the even more
minimal lowlogic option. When done, the -- line specifies that all the
tasks join together again for the lines following.
full_proof:
chparam -set IMPLEMENT_MPY 1 zipcpu
chparam -set IMPLEMENT_DIVIDE 1 zipcpu
chparam -set EARLY_BRANCHING 1 zipcpu
chparam -set OPT_CIS 1 zipcpu
chparam -set OPT_PIPELINED 1 zipcpu
nopipe:
chparam -set IMPLEMENT_MPY 0 zipcpu
chparam -set IMPLEMENT_DIVIDE 0 zipcpu
chparam -set EARLY_BRANCHING 0 zipcpu
chparam -set OPT_CIS 1 zipcpu
chparam -set OPT_PIPELINED 0 zipcpu
lowlogic:
chparam -set OPT_CIS 0 zipcpu
--
prep -top zipcpuNow, just the one command
% sby -f zipcpu.sbywill attempt to
formally verify
the entire
ZipCPU in all of these various
configurations. For each configuration,
SymbiYosys
will create a directory,
such as zipcpu_dcache, zipcpu_full, or zipcpu_lowlogic. Within this
directory, you’ll find the logfile.txt containing the standard output from
the run. You can use this to find out whether your design passed that proof,
or if not what assertion or cover statement failed. You’ll also find an
engine_0 directory with any trace files within it. (Why engine_0?
Because I tend to only ever use one
formally verification
engine. Otherwise you might have other engines as well.)
Using Make to drive SymbiYosys
There’s one other thing
SymbiYosys
provides that is very valuable from a scripting standpoint. Upon
completion,
SymbiYosys
will create an empty file in the newly created results
directory indicating the results of the run. Example files include
ERROR, FAIL, PASS, and UNKNOWN. This file makes it easy to create a
Makefile.
to support several
SymbiYosys
runs, and we only need use the PASS file to do it.
Let’s pick an example component to verify, such as the ZipTimer that we discussed earlier. The timer itself has no real configuration options, so to verify it we could just place the following two lines into our Makefile.
ziptimer:
sby -f ziptimer.sbySymbiYosys,
however, will make a directory called ziptimer upon every run.
Once this directory exists, make will no longer run our proof. However, if
we tell make that ziptimer is just a
name of something to do and not a file, we can create the functionality we want.
.PHONY: ziptimer
ziptimer:
sby -f ziptimer.sbyThis Makefile
will now command a
SymbiYosys,
proof everytime we try to make the ziptimer target.
But what if the ZipTimer hasn’t changed? Why should we re-verify it if the code within it hasn’t changed, and if it passed the last time?
Here is where make starts to shine. Since ziptimer/PASS is a file, created
upon successful completion of the
formally verification
pass, we can tell
make
that this file is created from the files the
ZipTimer.
depends upon.
.PHONY: ziptimer
ziptimer: ziptimer/PASS
ziptimer/PASS: ../../rtl/peripherals/ziptimer.v
sby -f ziptimer.sbyNow, anytime the
ziptimer.v file
changes, make will attempt to
formally verify
it again. Further, should the proof fail, the PASS file will not get
created, and so the next time we call
make it will attempt to create this
file again until our proof passes.
What if we wanted to verify a lot of things? Rather than running make many times, once per target, we might instead start our Makefile with a list of proofs, containing both the components as well as larger proofs.
TESTS : ziptimer
TESTS += zipcpu
all: $(TESTS)Now, if all is the default make target,
as defined by being the first target within our
Makefile,
then all of the tests named in $(TESTS) will get built, er … verified.
Let’s clean this up a little more with some definitions. Since I like to keep
my formal verification
scripts
separate from my Verilog
files, it might help
to use a name for that path to simplify it. Here, we use RTL. Once
defined, this value will get substituted anytime we reference $(RTL).
Likewise we’ll shorten the name of our target ziptimer to $(TMR).
RTL := ../../rtl
TMR := ziptimerWe can also define the names of our formal wishbone property sets.
MASTER := $(RTL)/ex/fwb_master.v
SLAVE := $(RTL)/ex/fwb_slave.vPutting all this together, the script now says that …
$(TMR)is a “phony” target that doesn’t build a file.
.PHONY: $(TMR)- To build
$(TMR)we need to first build$(TMR)/PASS. Why the extra step? Just so that we can runmake ziptimerlater, rather thanmake ziptimer/PASSor worsemake ziptimer_timerconfiguration/PASSfor every timer configuration we might have.
$(TMR): $(TMR)/PASS- Finally, we can call
SymbiYosys
to formally verify
our timer.
This proof is dependent upon not only the code for the timer
itself,
but also a list of formal wishbone
properties.
These are called dependency files, or sometimes just dependencies
for short, because the validity of our proof depends upon these files.
By listing these dependencies to the right of the
:, make will only formally verify our timer if either the$(TMR)/PASSfile is missing, or if one of the dependency files is newer than the$(TMR)/PASSfile.
$(TMR)/PASS: $(TMR).sby $(RTL)/peripherals/$(TMR).v $(SLAVE)
sby -f $(TMR).sbyThis is exactly what we want from a Makefile! Running make will run all of our formal verification proofs, but once all the logic is verified, running make will just return a message telling us it has nothing to do.
$ make
make: Nothing to be done for 'all'.
$But how shall we handle the multiple configurations we discussed earlier?
Why not set up one proof per configuration?
Let’s examine the proof of the
ZipCPU
core
itself. Remember how we had so many configurations above? What if the
PASS file associated with each configuration was a
make target?
CPU := zipcpu
# ...
.PHONY: $(CPU)
# Proofs to build
$(CPU): $(CPU)_dcache/PASS $(CPU)_piped/PASS
$(CPU): $(CPU)_nopipe/PASS $(CPU)_lowlogic/PASS $(CPU)_ice40/PASS
# Files the proofs depend upon
CPUDEPS:= $(RTL)/core/$(CPU).v $(RTL)/core/cpuops.v $(RTL)/core/idecode.v \
$(RTL)/core/pipemem.v $(RTL)/core/memops.v \
$(RTL)/ex/wbdblpriarb.v $(RTL)/ex/fwb_counter.v $(RTL)/cpudefs.v \
f_idecode.v abs_div.v abs_prefetch.v abs_mpy.v $(MASTER) $(SLAVE) \
$(CPU).sby
# Now one line for each proof, to build the respective <sbydir>/PASS files
$(CPU)_dcache/PASS: $(CPUDEPS)
sby -f $(CPU).sby dcache
$(CPU)_piped/PASS: $(CPUDEPS)
sby -f $(CPU).sby piped
$(CPU)_nopipe/PASS: $(CPUDEPS)
sby -f $(CPU).sby nopipe
# You should get the idea by this pointOnce accomplished, one simple command,
% makewill run all of the proofs we have described within our Makefile. This includes calling SymbiYosys to verify every one of the ZipCPU’s various configurations.
Once completed, or even before, you can run
% make -nto see what proofs have yet to be completed, or equivalently which proofs have failed–assuming in the latter case that make has completed.
Of course, the problem with using make -n to determine which proofs have
failed is what happens after only one proof fails. After the first proof
fails, make will give you no
information about whether or not the remaining proofs might pass.
Alternatively, if you don’t want
make to stop on the first failed proof,
you can instead run,
% make -kWant to use all of your host processors multiple cores? You could specify
make -k -j <ncpus> to use all <ncpus> of them. However, this might
leave some of your build cores overloaded during induction. For
this reason, I’ve considered running make -n -j <ncpus/2> instead.
What’s all this good for? Well, for me this means I can verify my brand new
data cache,
instruction cache,
instruction decoder,
several arbiters, … and the ZipCPU
itself
from one make command. If the make command fails, I can go back and
examine the respective logfile.txts to see why. Likewise, if I want
to know what proofs need to be re-accomplished, I can just type make -n
to see what make would try to build if you ran it again.
With a little more work, I could split the list of Verilog files, $(CPUDEPS),
into a more finer grained list, so that all of the CPU configurations
don’t need to be re-verified every time one file, used only by some
configurations, changes.
Conclusions
When I first started using this approach of testing multiple configurations
automatically using
make,
I immediately found several errors within code that I had assumed was working.
The first bug was in the memory
component,
where it wasn’t properly handling a misaligned address exception (an option
that wasn’t checked by default). The second bug was within the
I-cache,
that I am hoping to blog about soon. Since I had only verified the safety
properties within it, that is the assert()s given the assumptions, I hadn’t
noticed that certain assumptions rendered the proof
vacuous.
Now, using these multiple configurations, I can both prove the assertions
and run cover to be even more certain that the various
ZipCPU components work.
So even though I’ve only started using this approach in the most recent
release of the ZipCPU, because of the
bugs I’ve found with it using this new approach, I now like it so much that
I’m likely to slowly modify all of the
Makefiles
within my various projects to use this
approach as I have opportunity. Even if the core in question isn’t
configurable, I’m going to make certain I do this in order to guarantee that
the cover() checks run automatically.
Then I saw, and considered it well: I looked upon it, and received instruction. (Prov 24:32)